Bringing Deep Learning Workloads to JSC supercomputers
Parallelize Training
March 25th, 2025
What this code does
Again, this is not a deep learning course.
If you are not familiar with the model and the dataset, just imagine it as a black box: you provide it with text, and it generates another text.
![]()

Let’s have a look at the files
to_distrbuted_training.py and
run_to_distributed_training.sbatch in the
repo.

llview
- You can monitor your training using llview.
- Use your Judoor credentials to connect.
- Check the job number that you are intrested in.
![]()

llview
- Go to the right to open the PDF document.
It may take some time to load the job information, so please
wait until the icon turns blue.
![]()
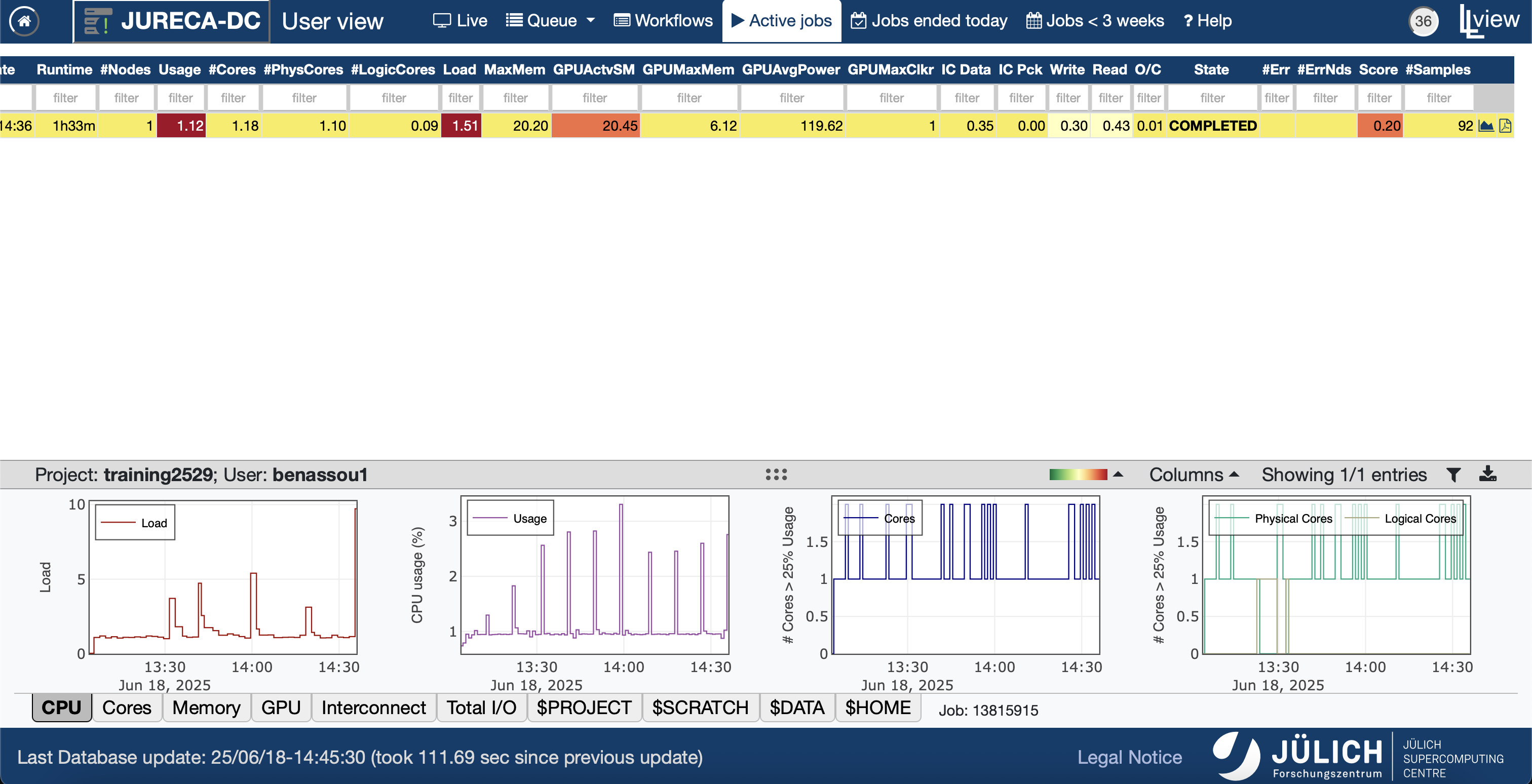
llview
- You have many information about your job once you
open the PDF file.
![]()
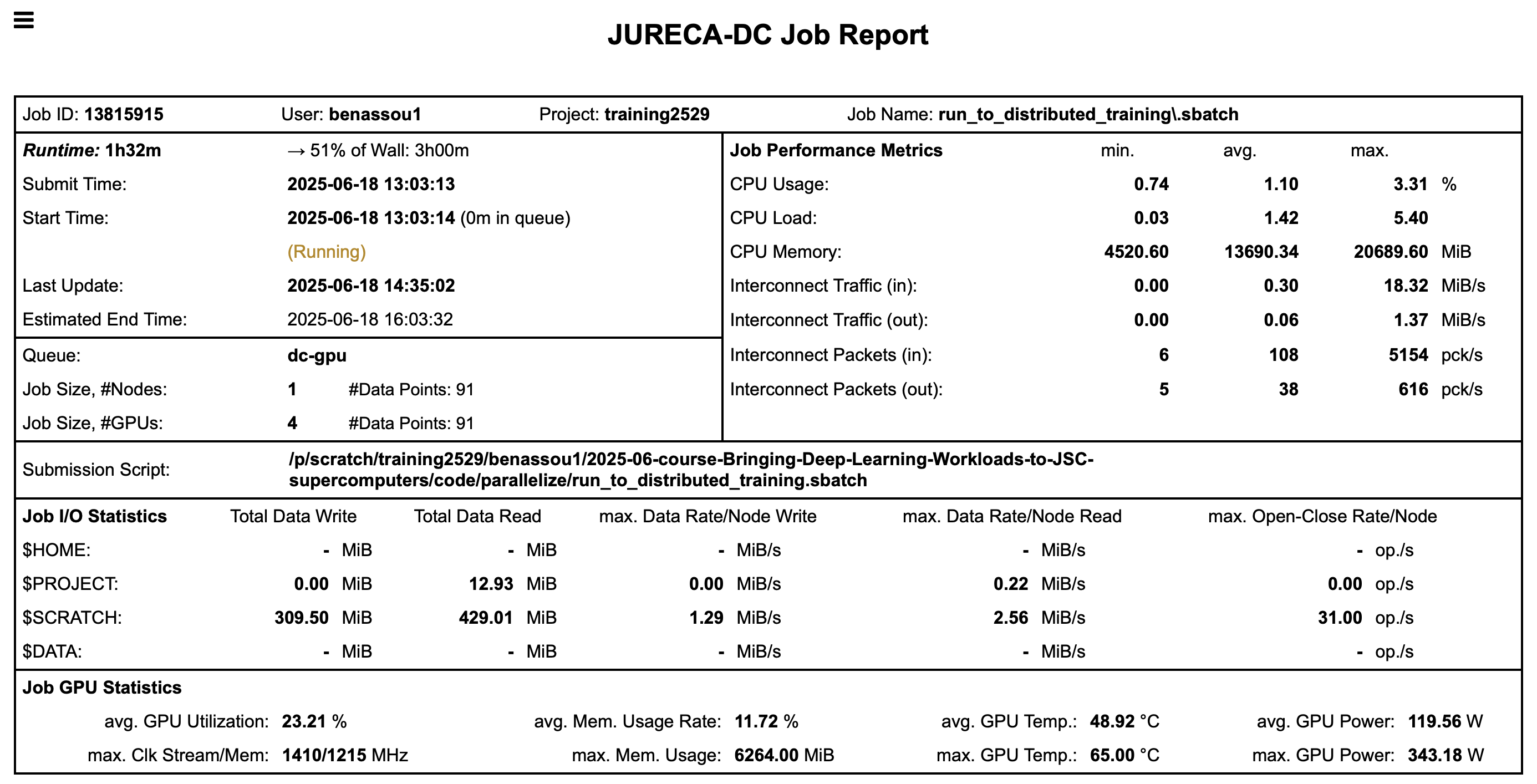
GPU utilization
You can see that in fact we are using 1 GPU
![]()
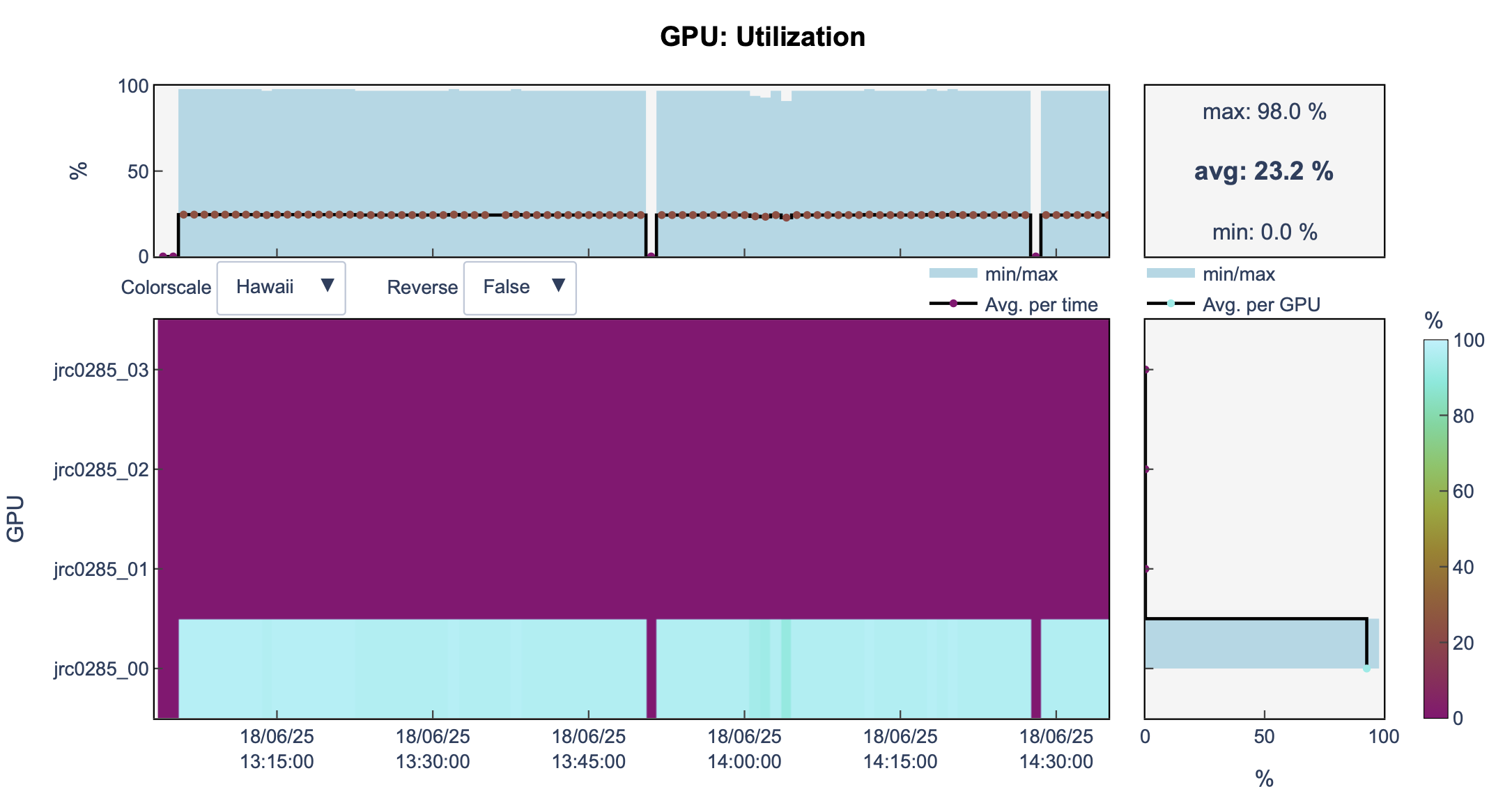
llview
We are still using 1 GPU
![]()
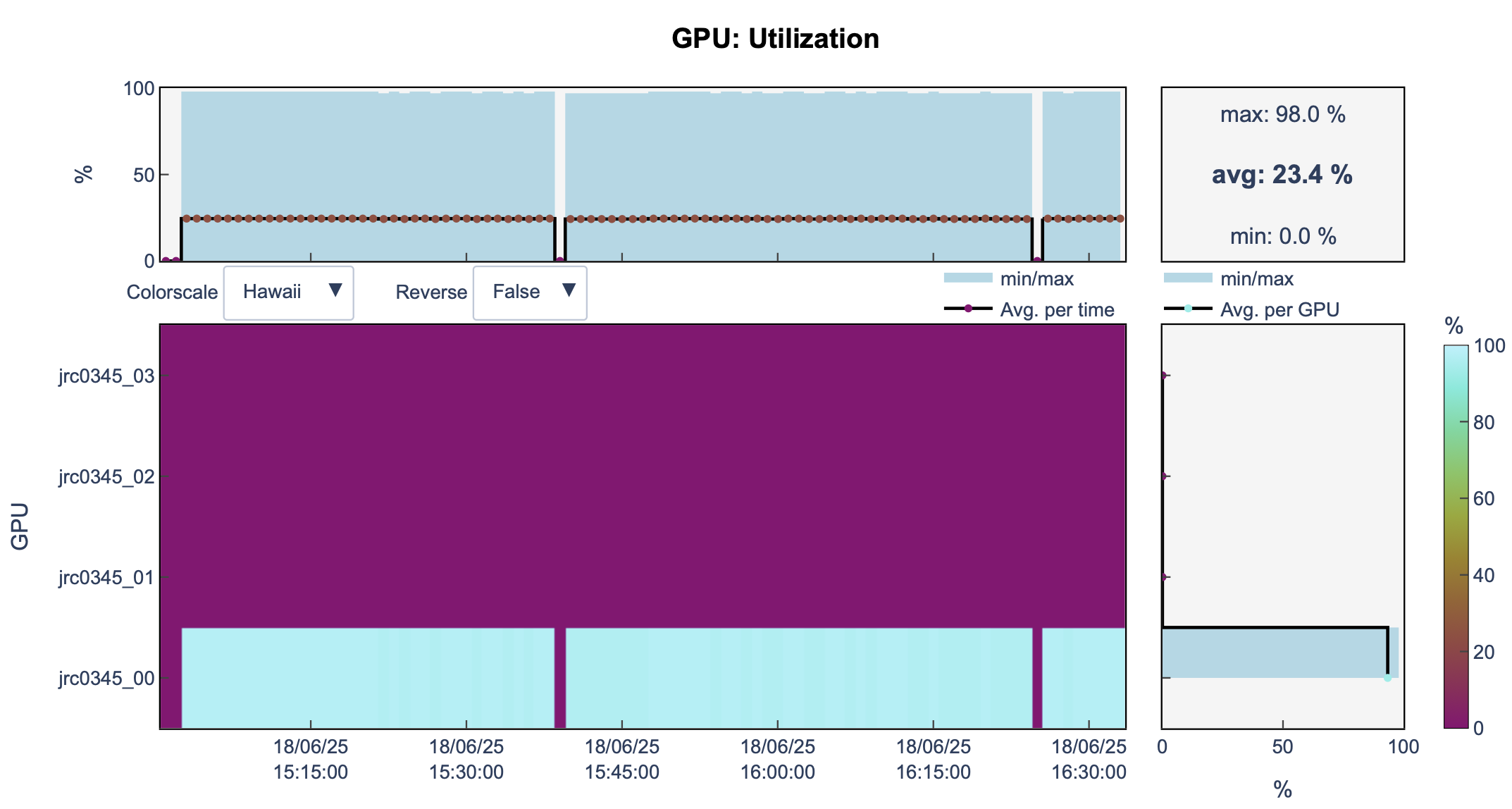
We need communication
Without correct setup, the GPUs might not be utilized.
Furthermore, we don’t have an established communication between the GPUs
![]()

We need communication

We need communication

All Reduce

- Other operations, such as min, max, and avg, can also be performed using All-Reduce.
All Gather

Reduce Scatter

World Size

Rank
![]()
local_rank
![]()
Distributed Data Parallel (DDP)
DDP is a method in parallel computing used to train deep learning models across multiple GPUs or nodes efficiently.

DDP

DDP

DDP

DDP

DDP

DDP

DDP

DDP

llview
Let’s have a look at our job using llview again.
You can see that now, we are using all the GPUs of the node
![]()
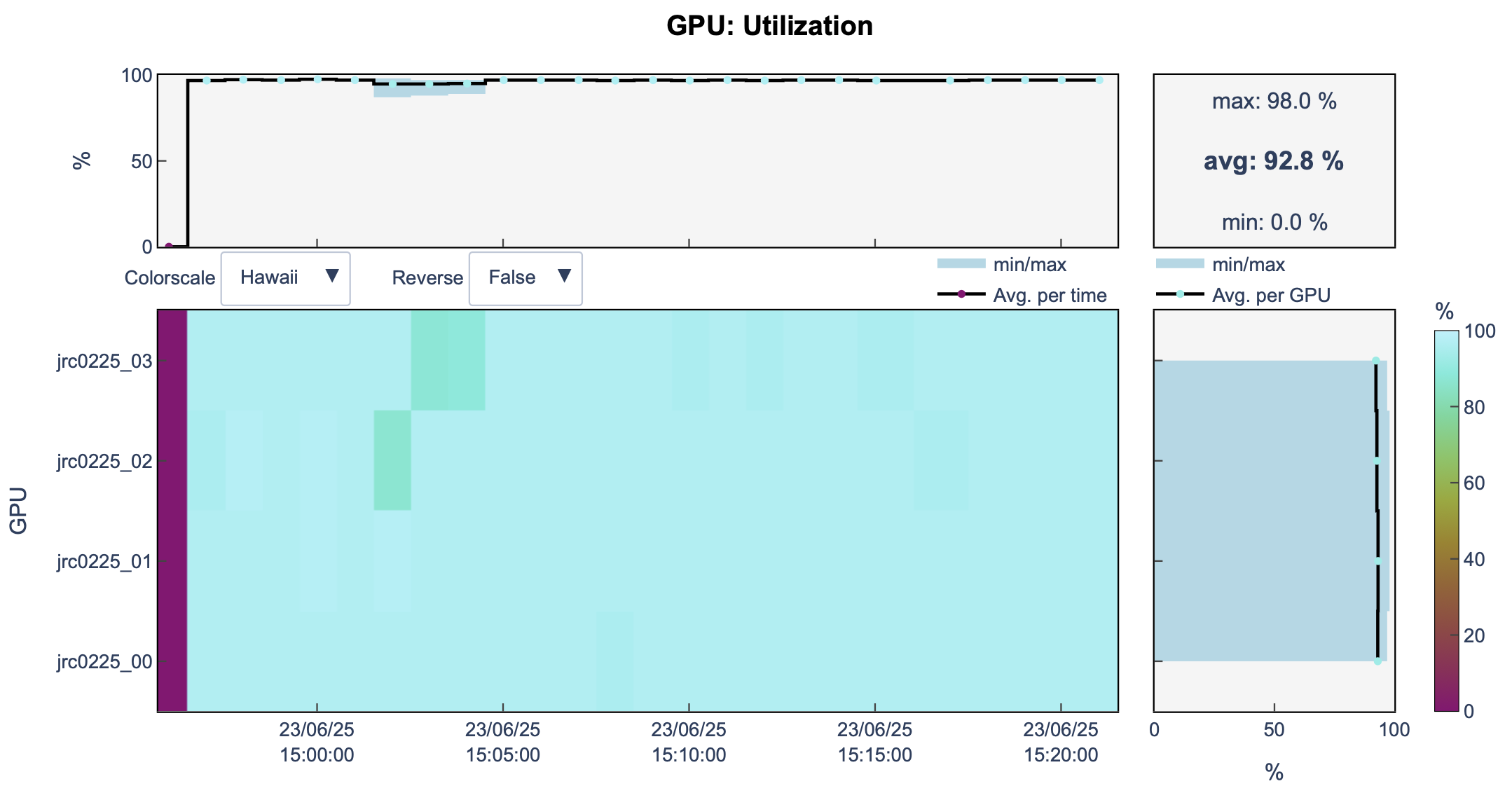
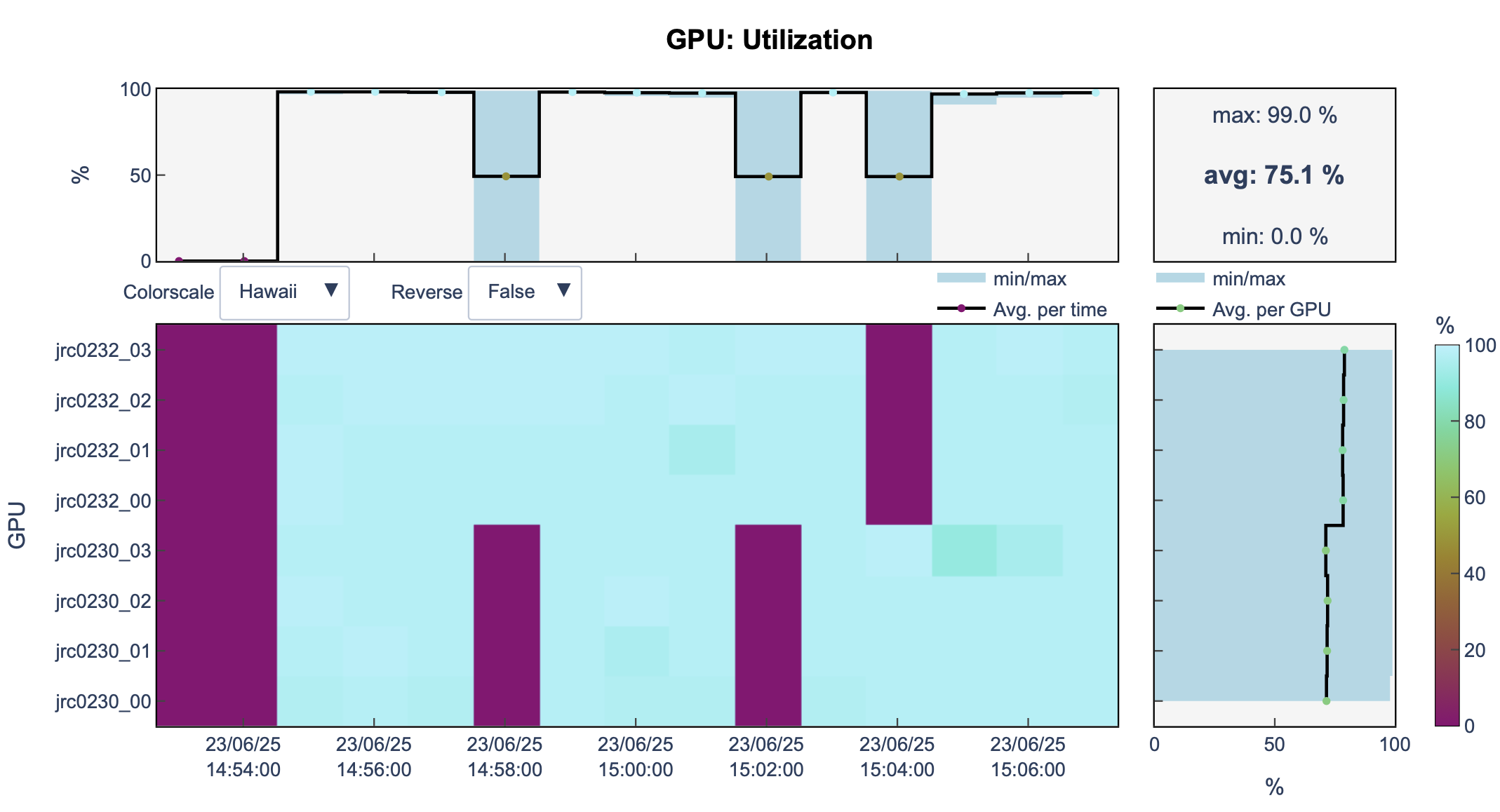
llview
Open llview again.
You can see that now, we are using 2 nodes and 8 GPUs.
![]()
And the training took less time (14m)
Fully Sharded Data Parallel (FSDP)


FSDP

FSDP

FSDP

FSDP

FSDP

FSDP

FSDP workflow

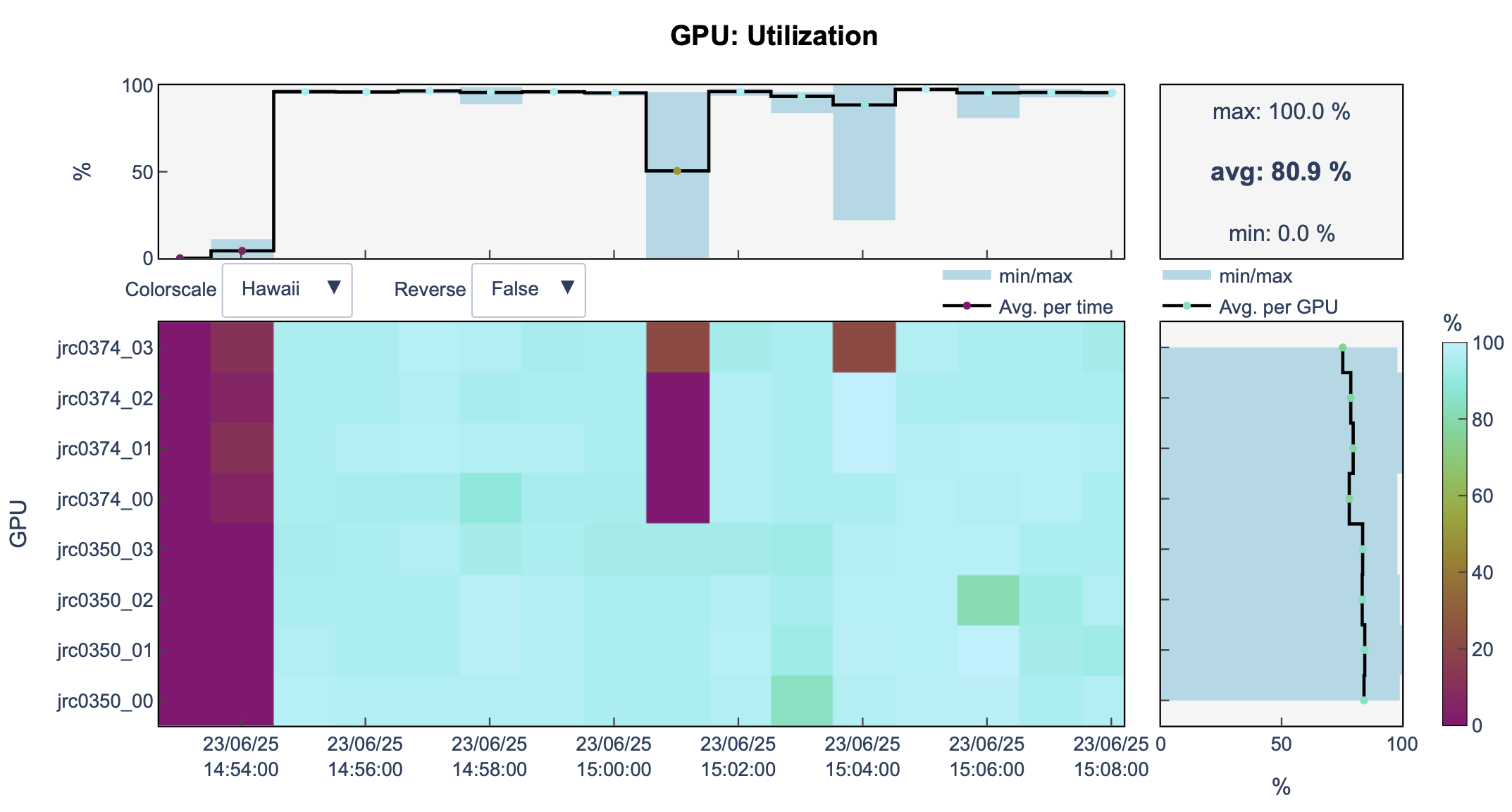
llview
Let’s have a look at llview again:
![]()
Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel

Model Parallel
- Waste of resources
- While one GPU is working, others are waiting the whole process to end
![]()
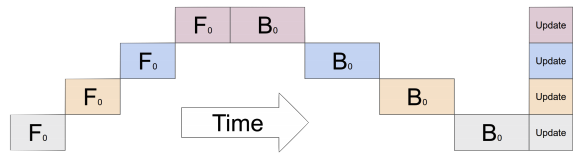
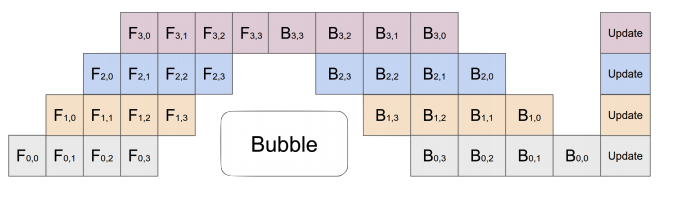
Model Parallel - Pipelining
Model Parallel - Pipelining

Model Parallel - Pipelining

Model Parallel - Pipelining

Model Parallel - Pipelining

Model Parallel - Pipelining

Model Parallel - Pipelining

Model Parallel - Pipelining

Model Parallel - Pipelining

This is an oversimplification!
- Actually, you split the input minibatch into multiple microbatches.
- There’s still idle time - an unavoidable “bubble” 🫧
![]()
Model Parallel - Multi Node

Tensor Parallelism (TP)
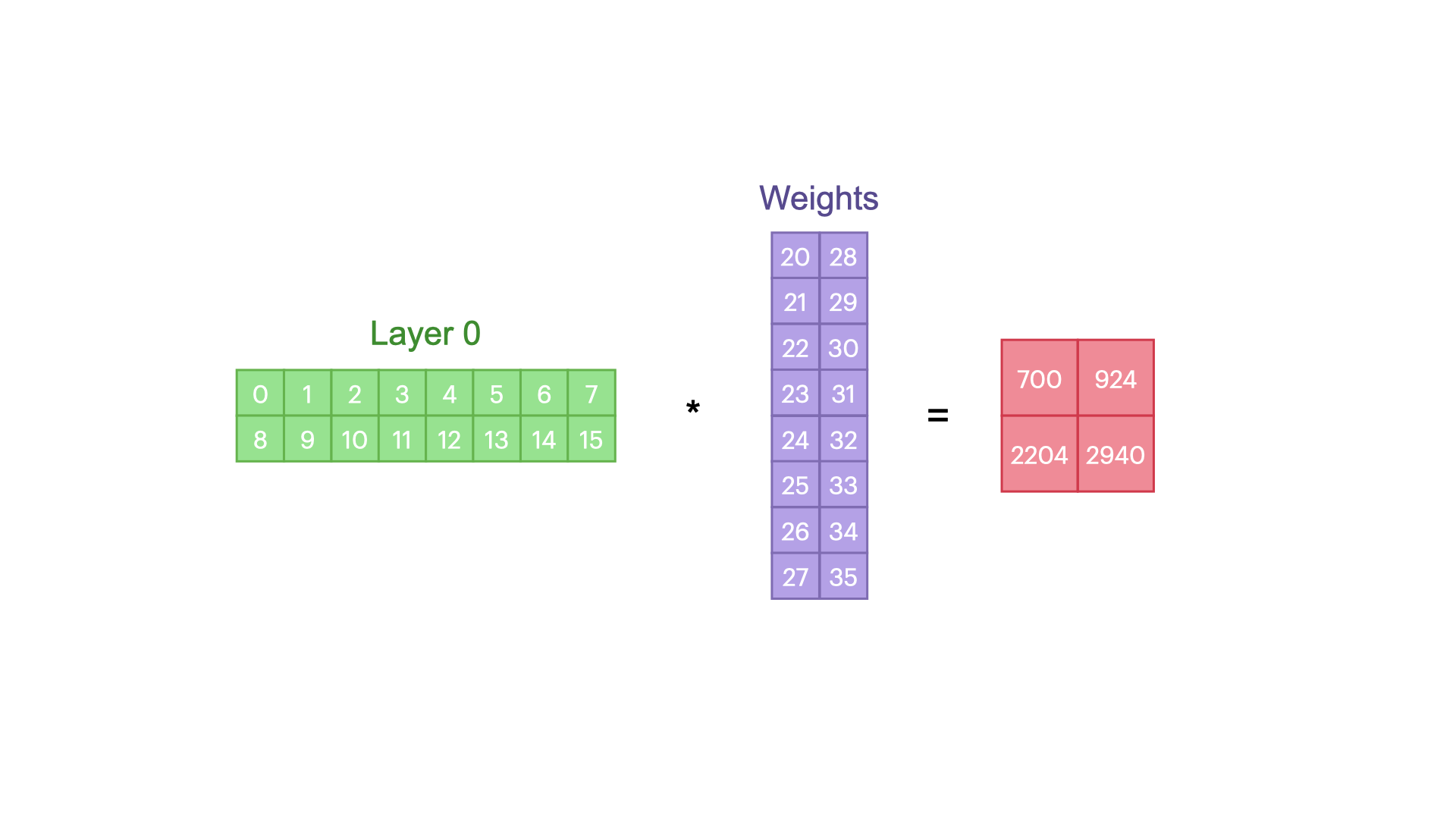
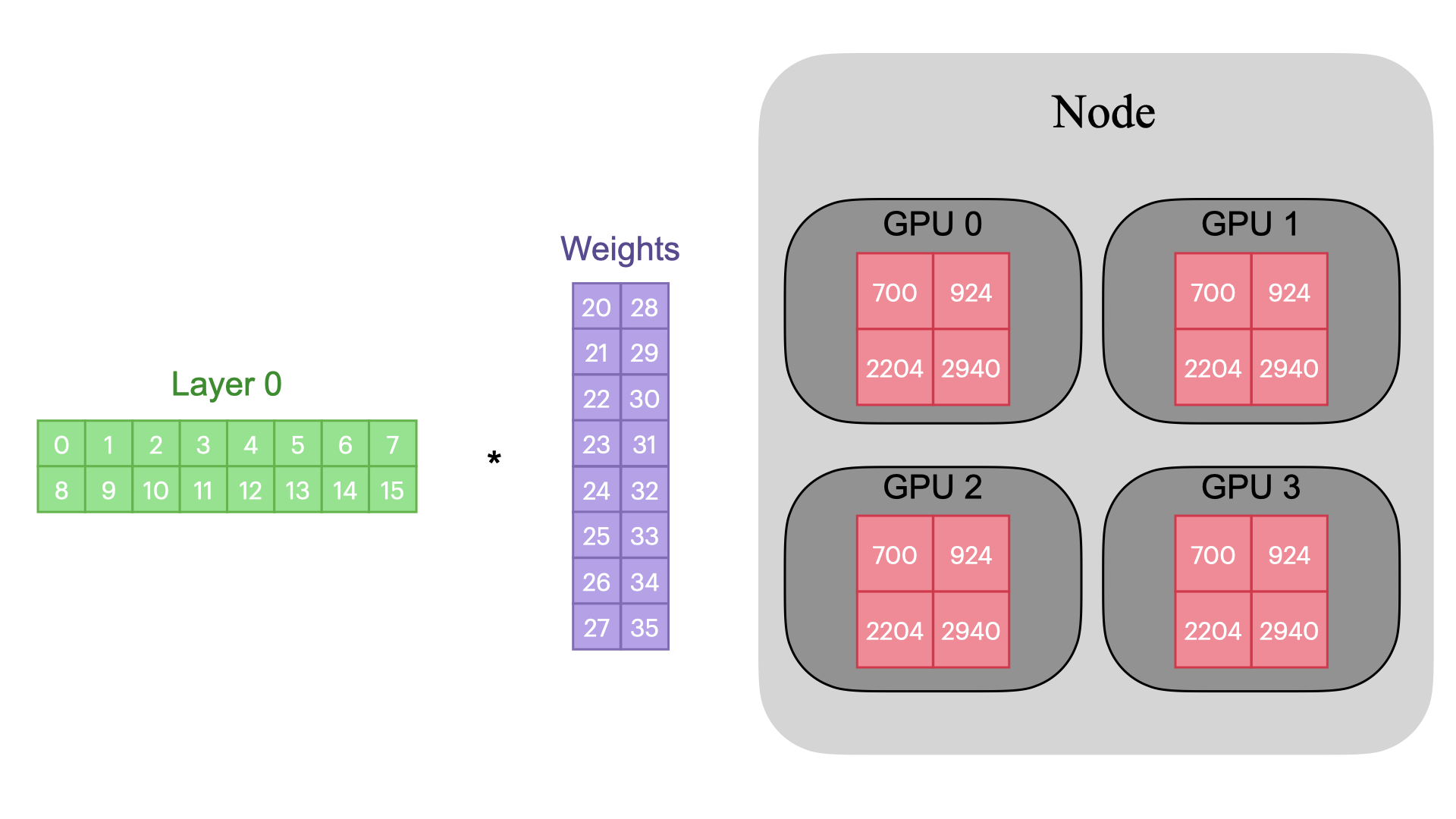
TP
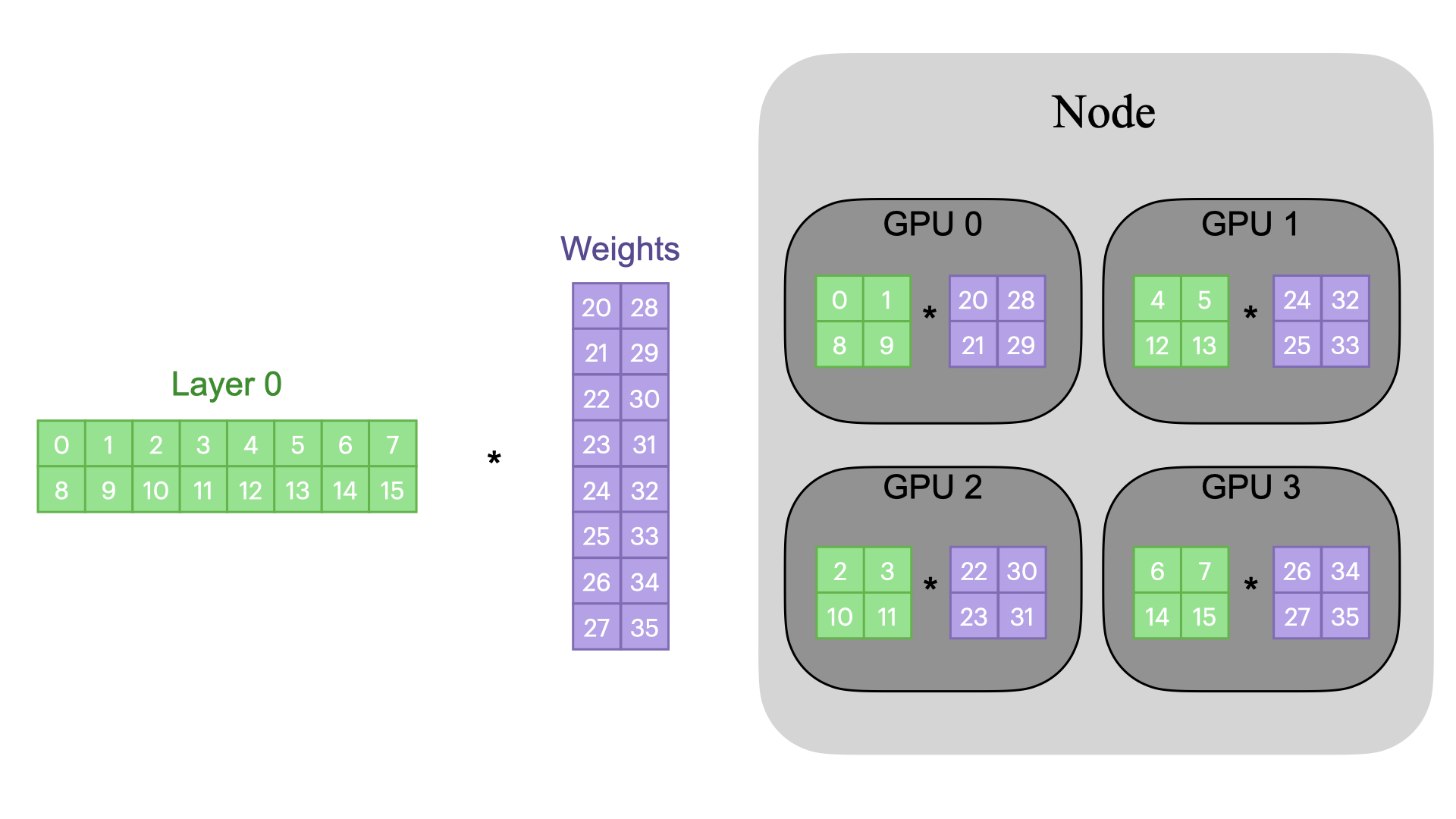
TP
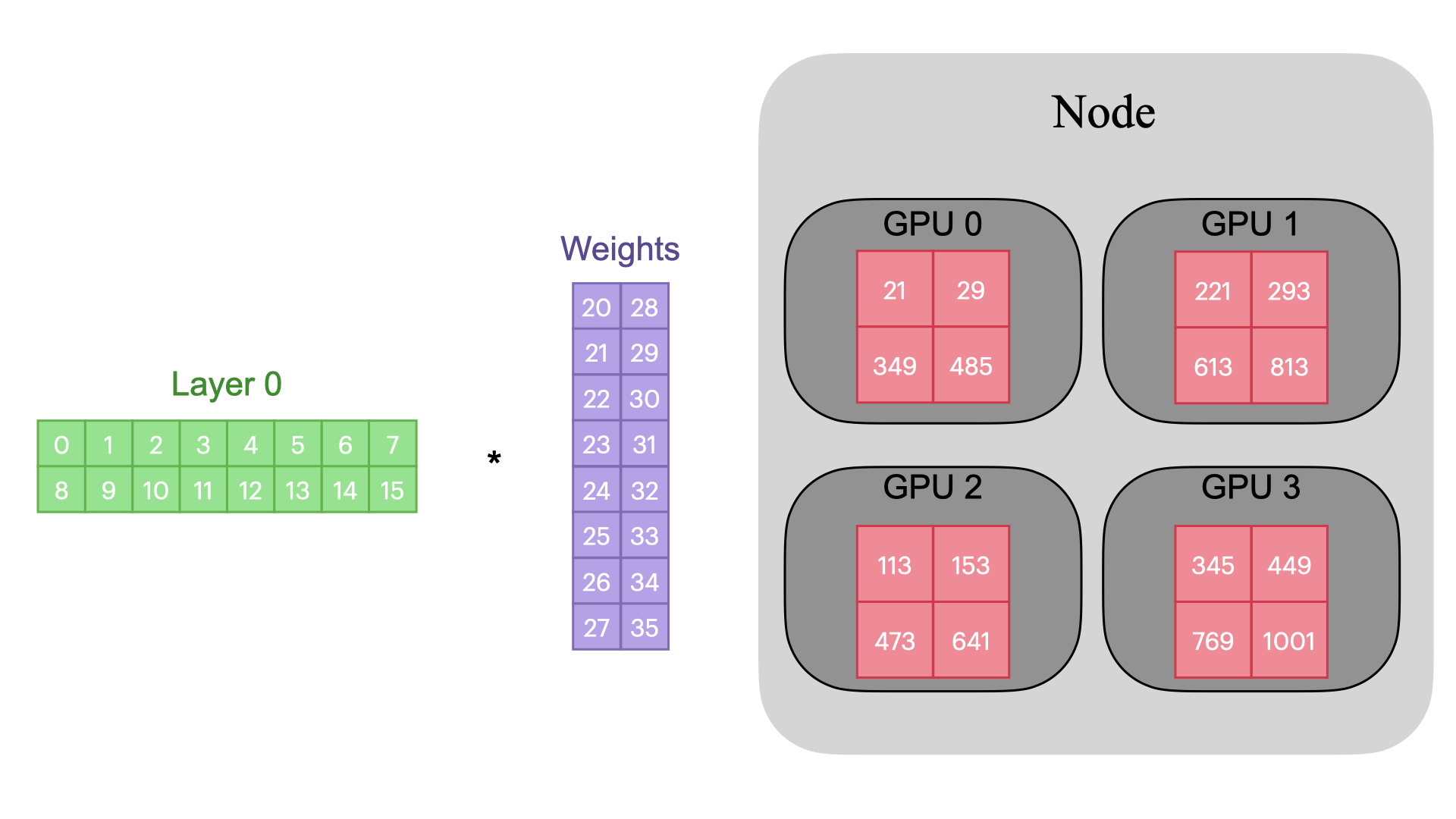
TP
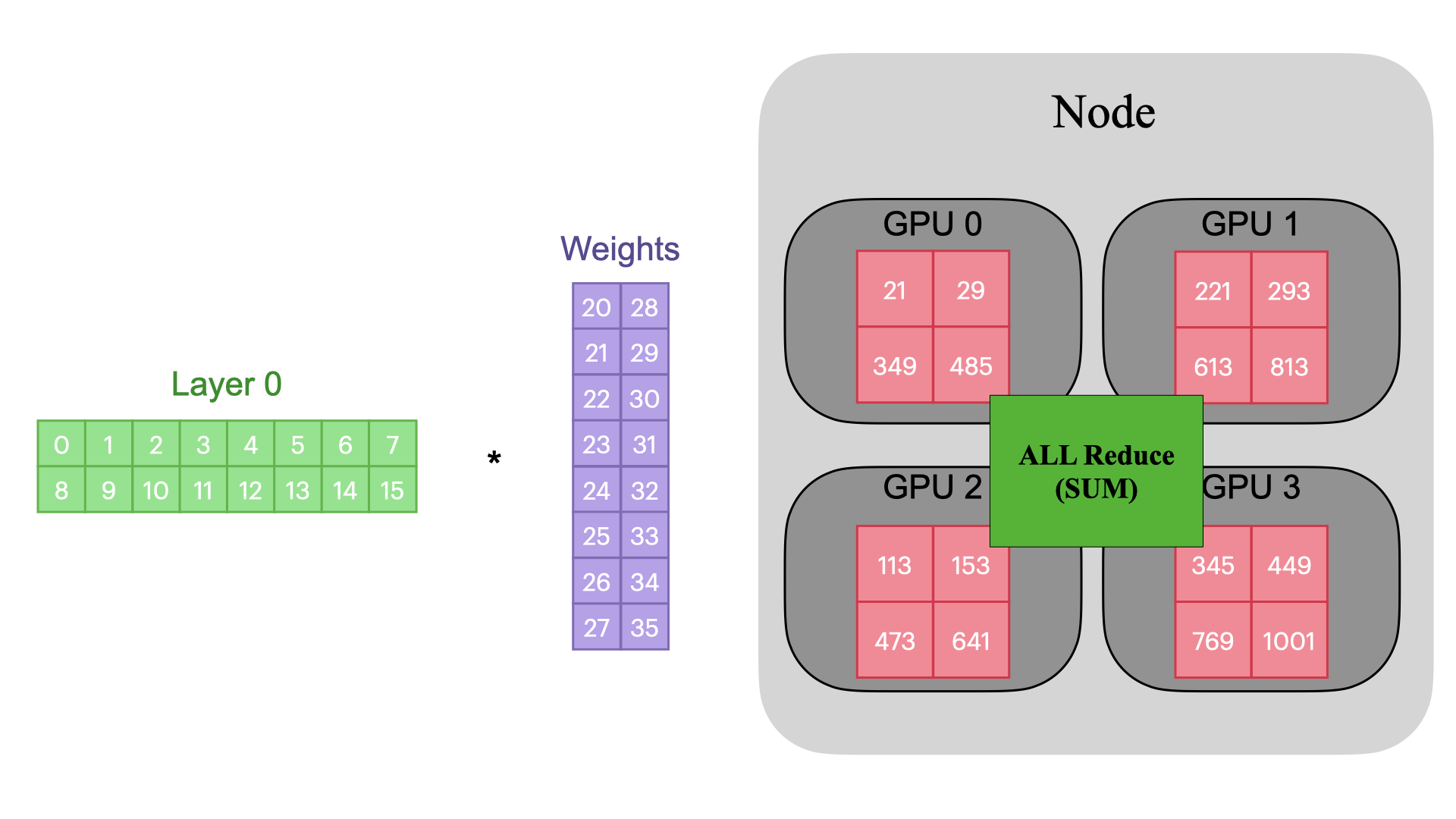
TP
3D Parallelism
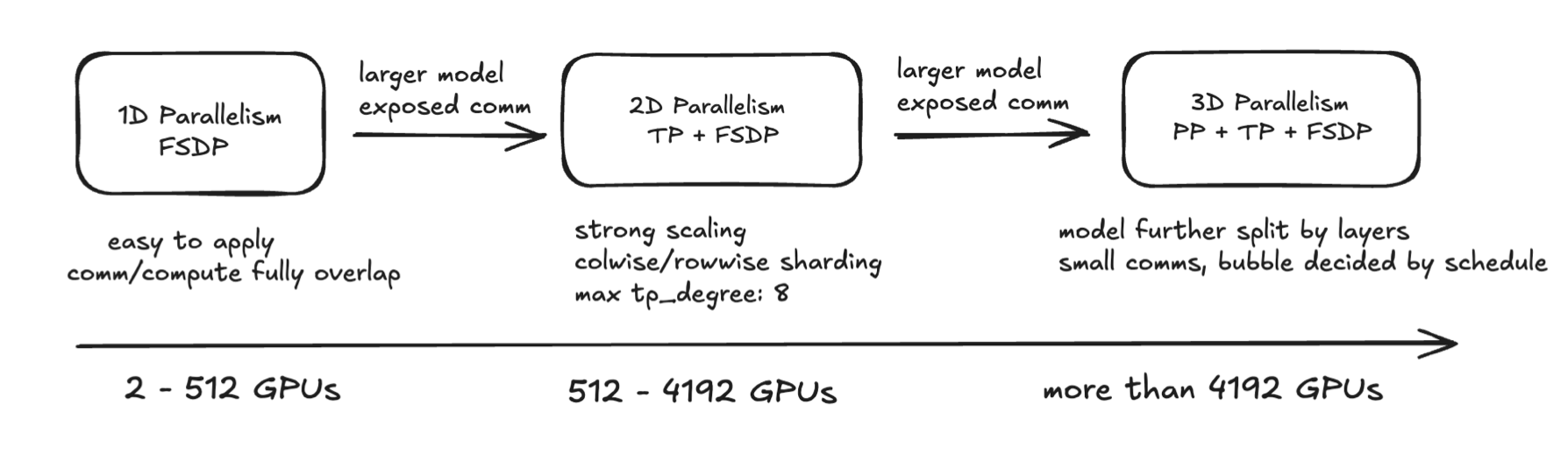
- 3D Parallelism combines Tensor Parallelism (TP), Pipeline Parallelism (PP), and Data Parallelism (DP) to efficiently train large models by distributing computation, memory, and data across multiple GPUs.
- It enables scaling to very large models by addressing compute, memory, and communication bottlenecks in a balanced way.