Bringing Deep Learning Workloads to JSC supercomputers
Data loading
June 25th, 2025
Let’s talk about DATA

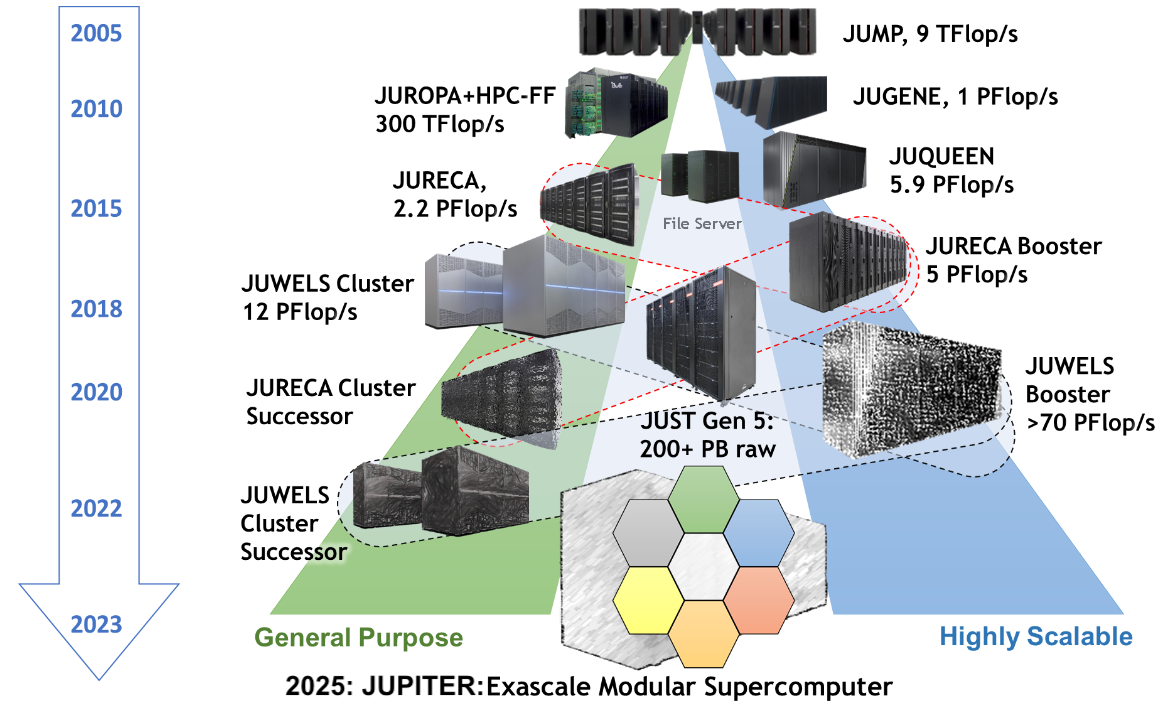
I/O is separate and shared
- All compute nodes of all supercomputers see the same files
- Performance tradeoff between shared acessibility and speed
- Our I/O server is almost a supercomputer by itself
![JSC Supercomputer Stragegy]()
Inodes
- Inodes (Index Nodes) are data structures that store metadata about files and directories.
- Unique identification of files and directories within the file system.
- Efficient management and retrieval of file metadata.
- Essential for file operations like opening, reading, and writing.
- Limitations:
- Fixed Number: Limited number of inodes; no new files if exhausted, even with free disk space.
- Space Consumption: Inodes consume
disk space, balancing is needed for efficiency.
![]()

The ImageNet dataset
Large Scale Visual Recognition Challenge (ILSVRC)
- An image dataset organized according to the WordNet hierarchy.
- Extensively used in algorithms for object detection and image classification at large scale.
- It has 1000 classes, that comprises 1.2 million images for training, and 50,000 images for the validation set.

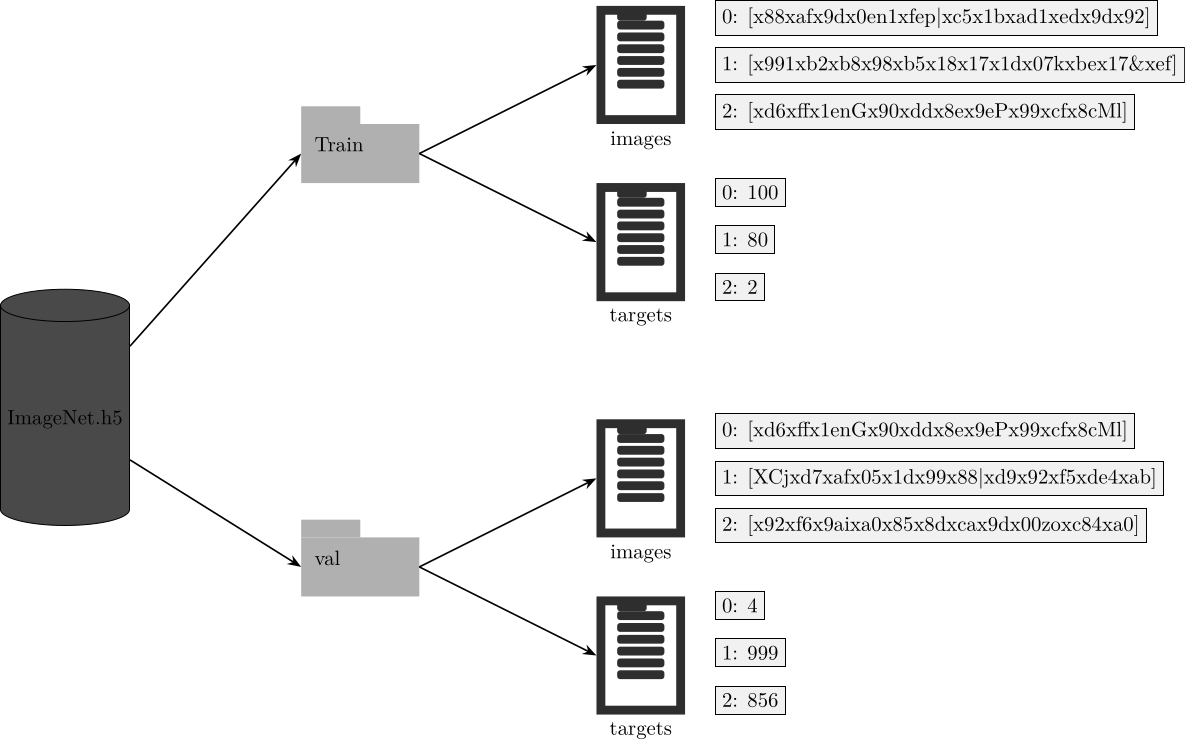
HDF5
PyArrow