Go to the right to open the PDF document.
It may take some time to load the job information, so please
wait until the icon turns blue.
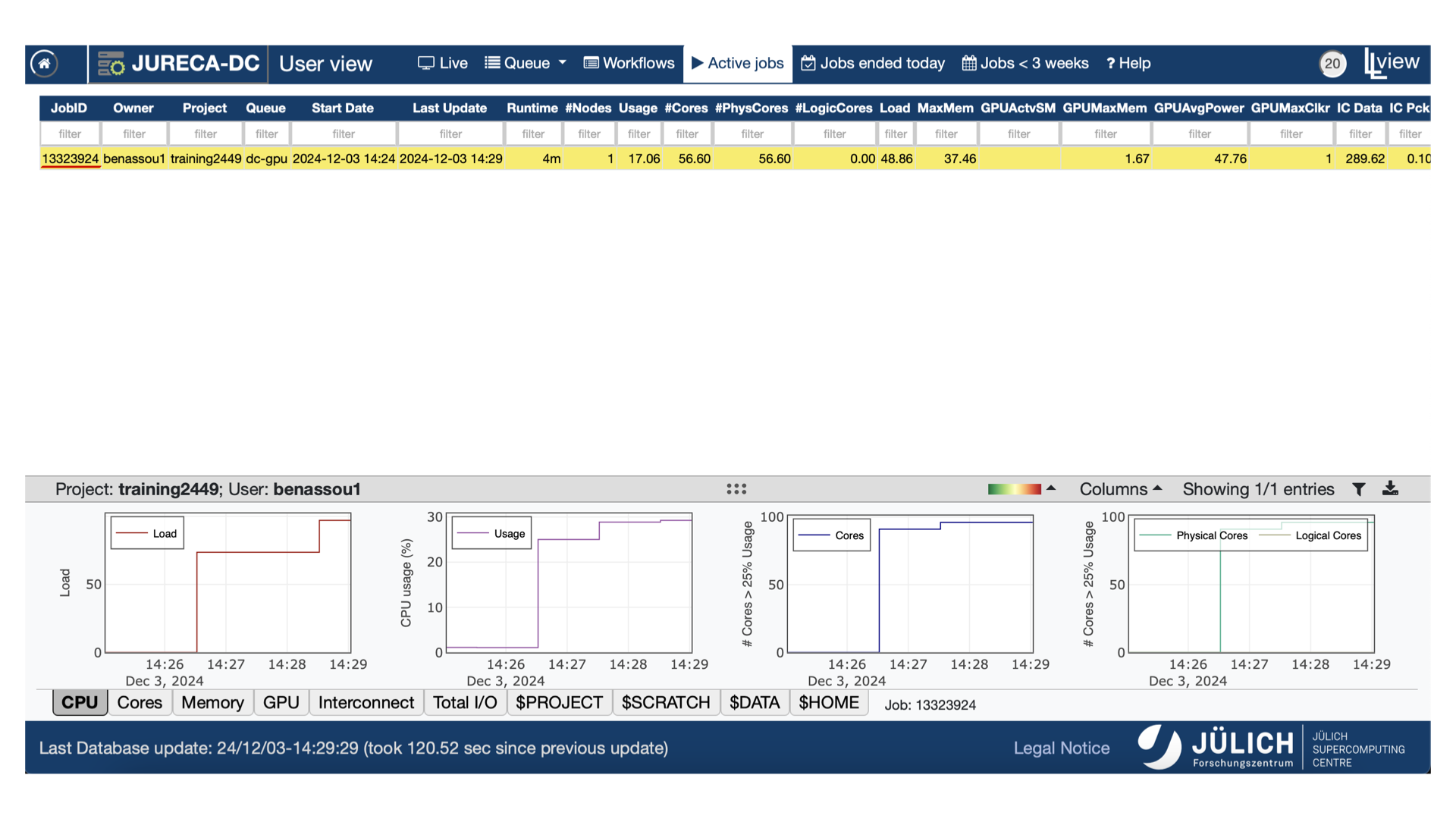
llview
You have many information about your job once you
open the PDF file.
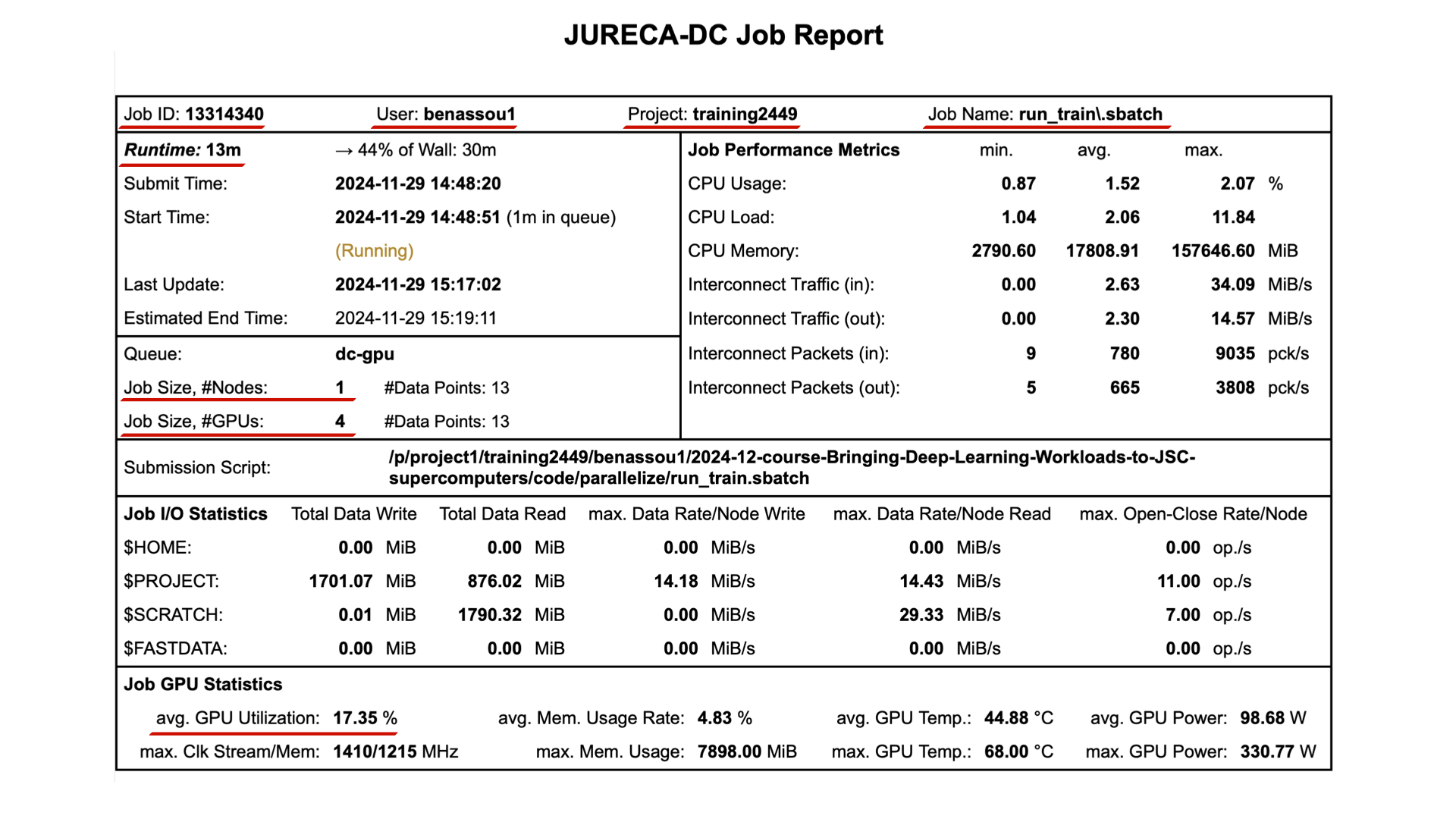
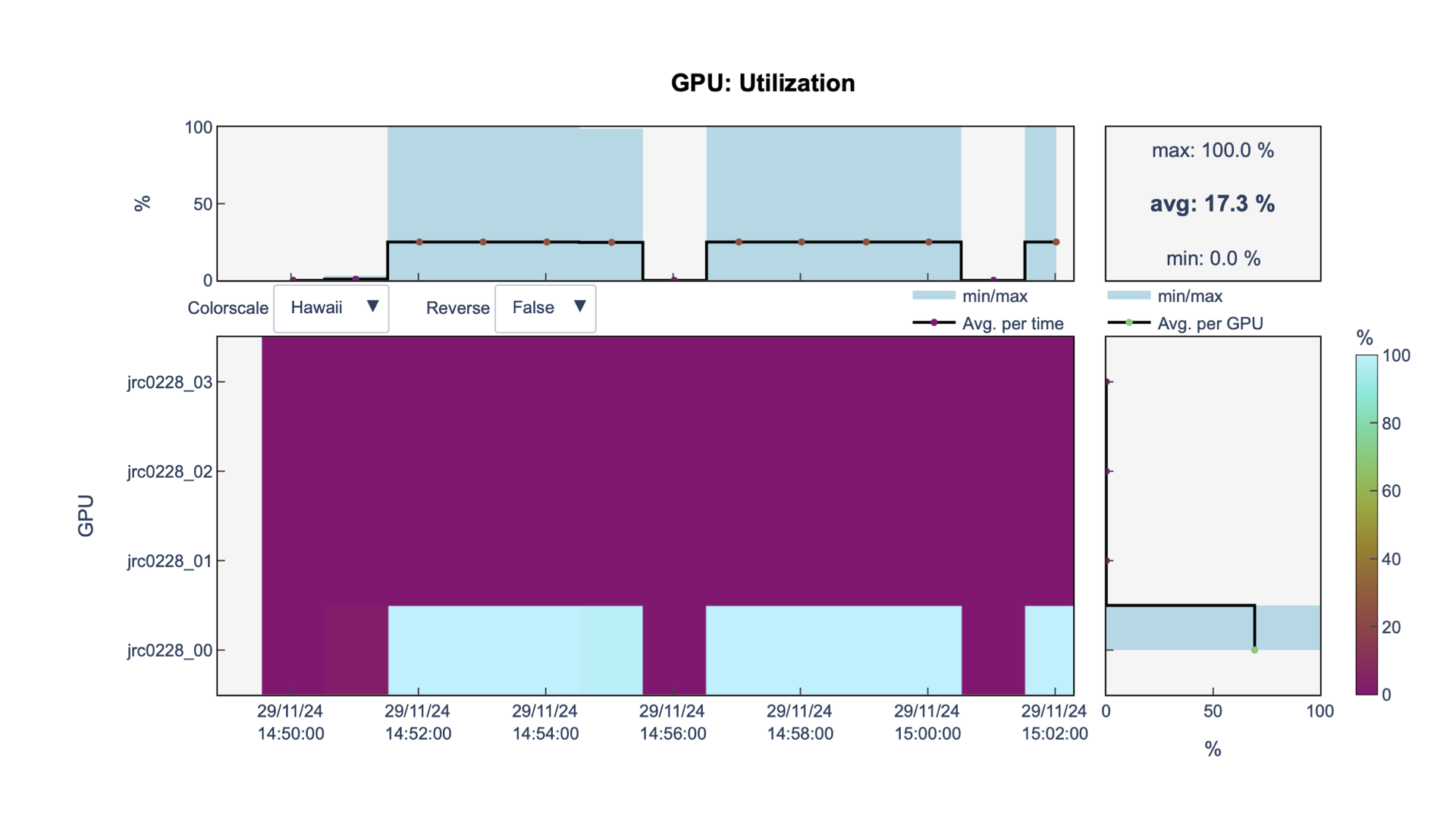
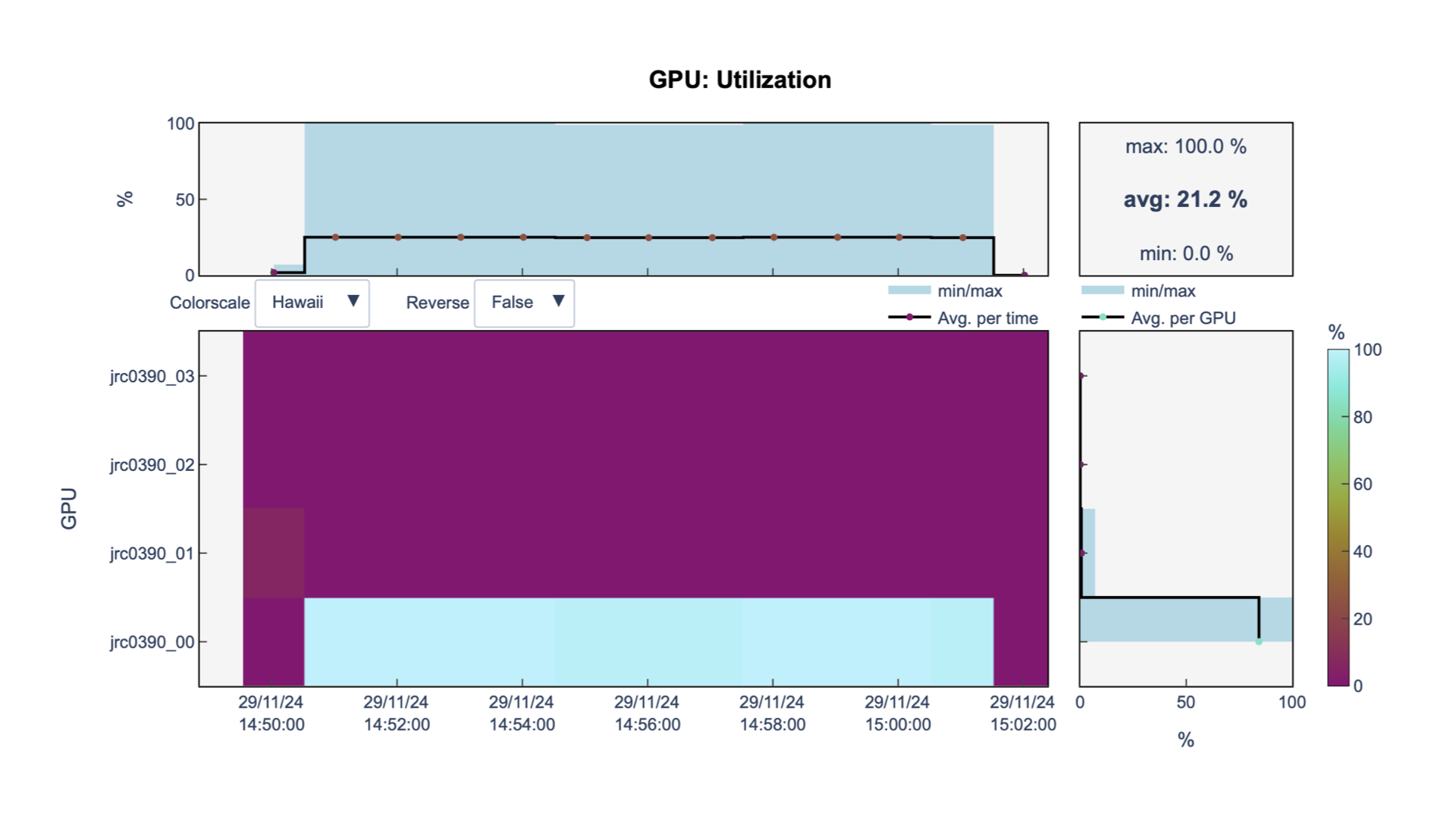
GPU utilization
You can see that in fact we are using 1
GPU
GPU utilization
It is a waste of resources.
The training takes time (13m according to
llview).
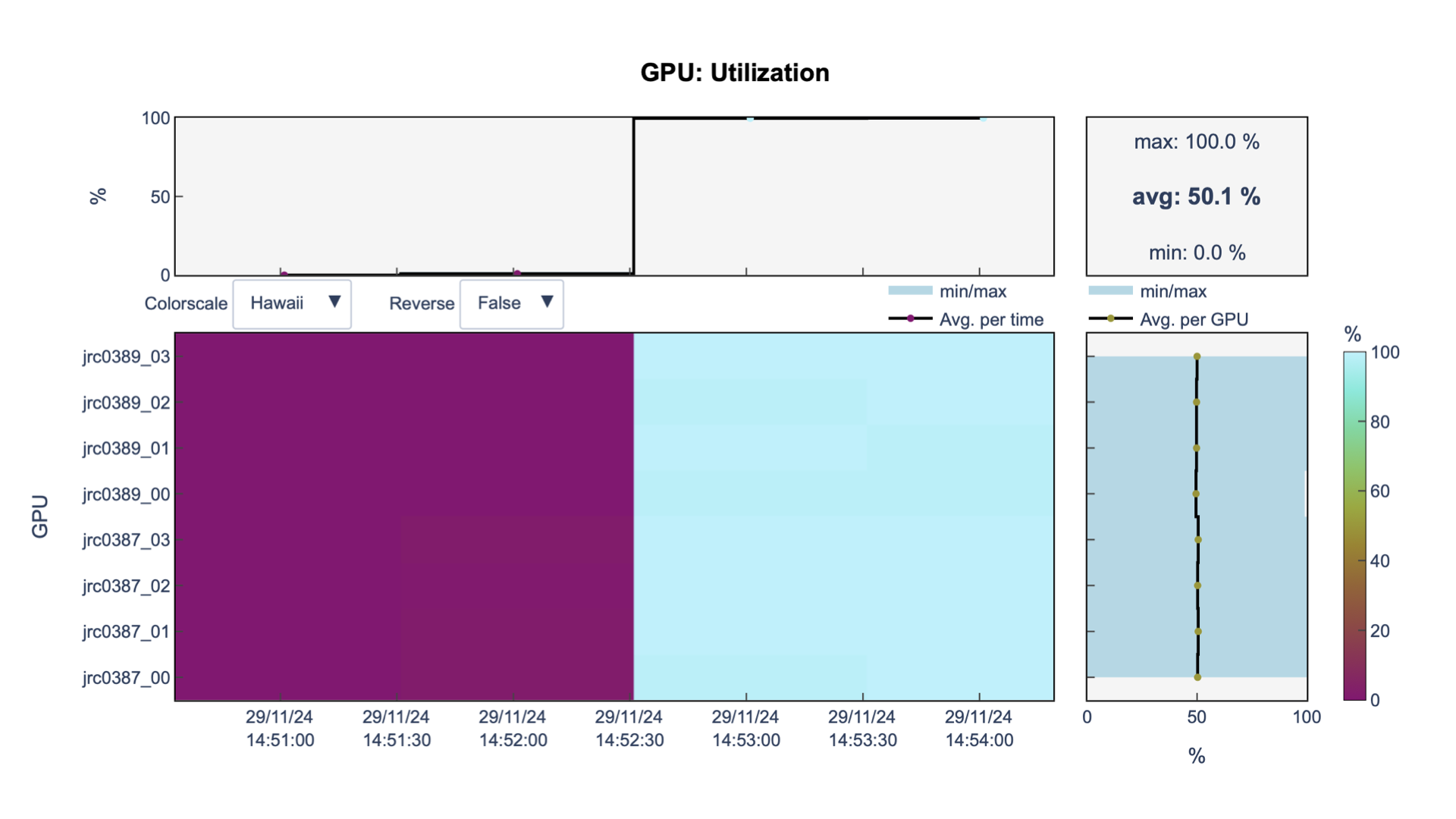
Then, can we run our model on multiple GPUs
?
What if
In file
run_train.sbatch, we increase the number
of GPUs at line 3 to 4:
#SBATCH --gres=gpu:4
And run our job again
sbatch run_train.sbatch
llview
We are still using 1
GPU
We need communication
Without correct setup, the GPUs might not be
utilized.
Furthermore, we don’t have an established
communication between the GPUs
We need communication
We need communication
collective operations
The GPUs use collective operations to communicate
and share data in parallel computing
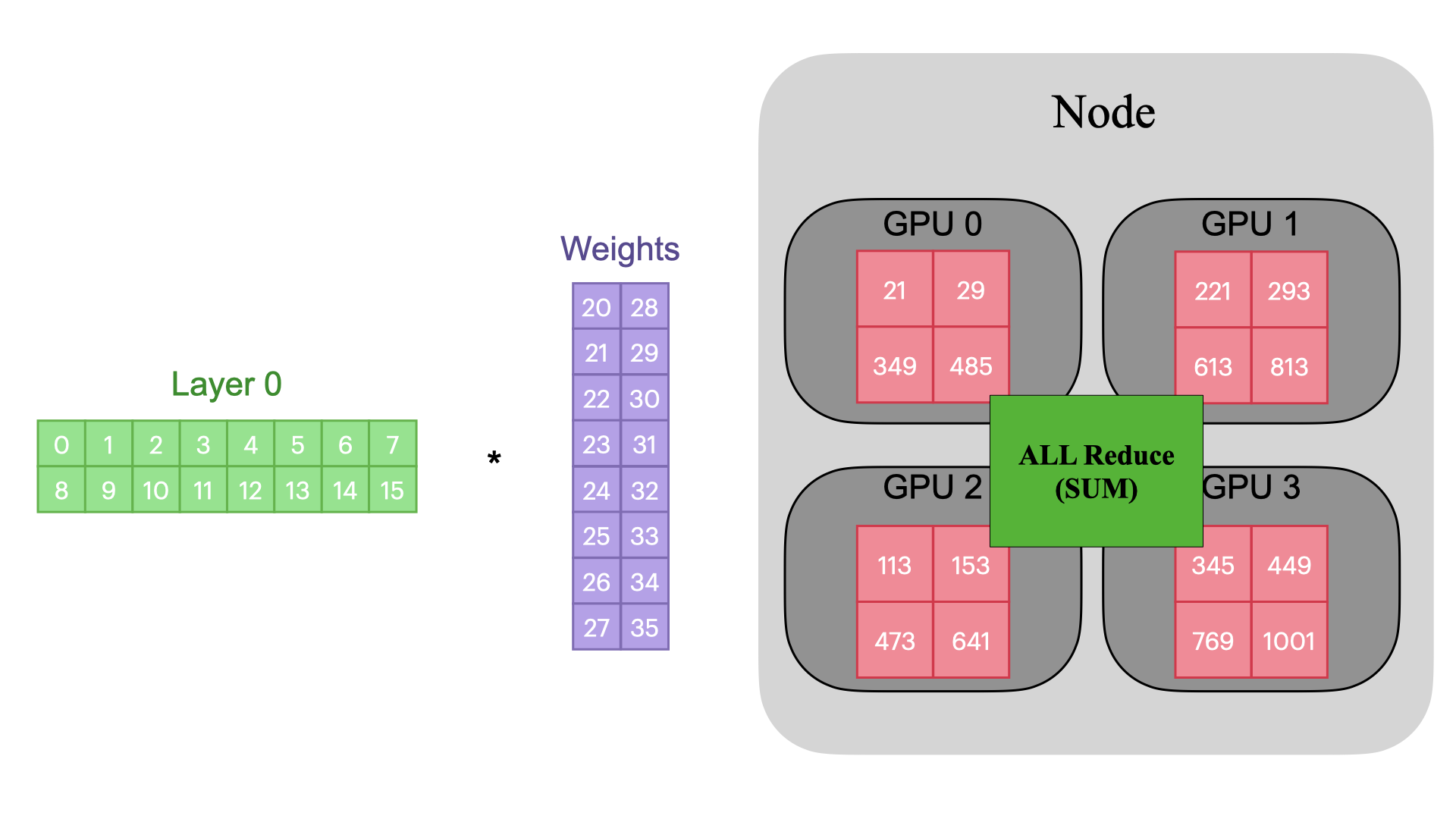
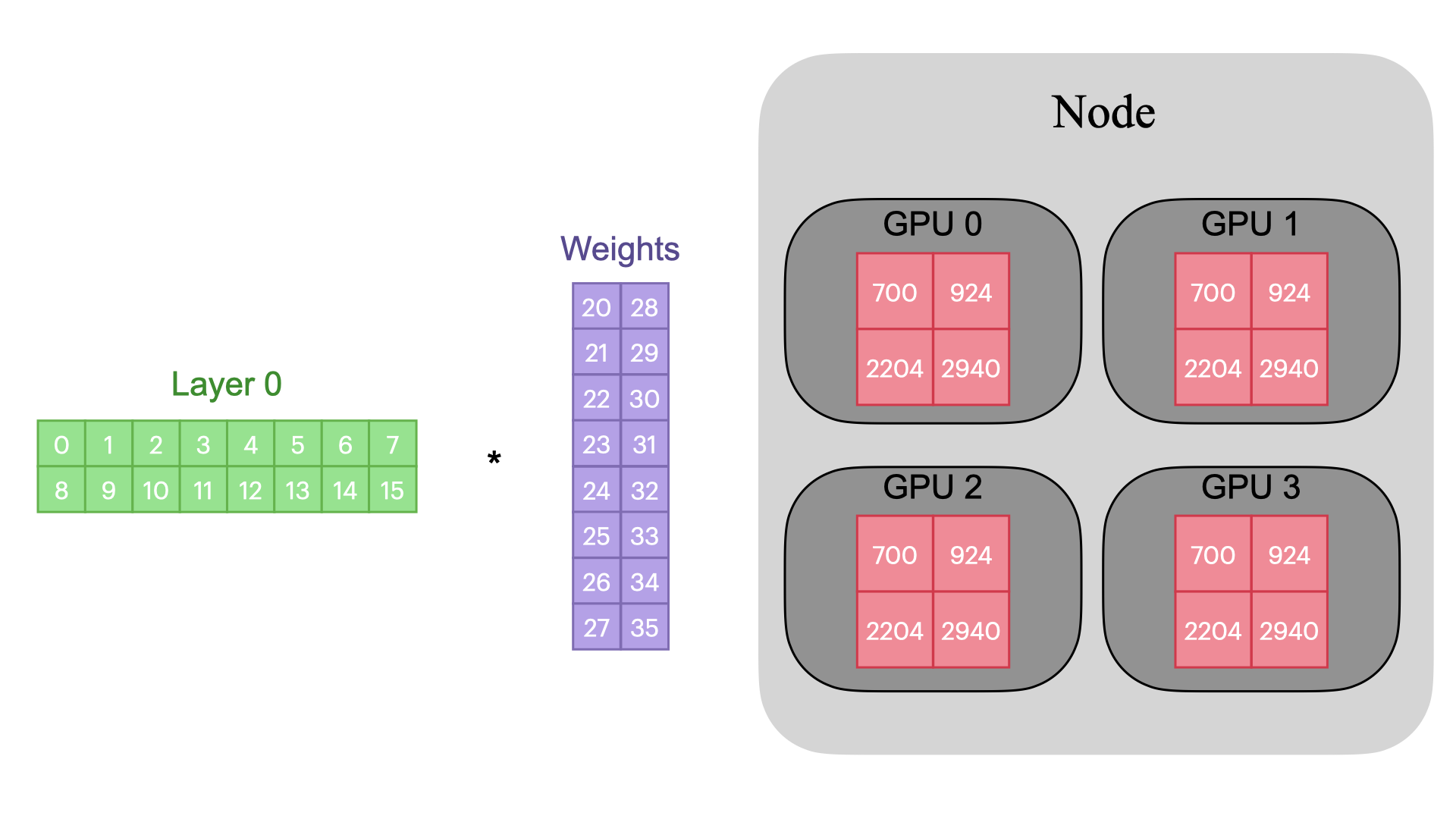
The most common collective operations are: All
Reduce, All Gather, and Reduce Scatter
All Reduce
Other operations, such as min,
max, and avg, can also be performed
using All-Reduce.
All Gather
Reduce Scatter
Terminologies
Before going further, we need to learn some
terminologies
World Size
Rank
local_rank
Now
That we have understood how the devices communicate and the
terminologies used in parallel computing, we can move on to distributed
training (training on multiple GPUs).
Distributed Training
Parallelize the training across multiple
nodes,
Significantly enhancing training speed and model
accuracy.
It is particularly beneficial for large models and
computationally intensive tasks, such as deep learning.[1]
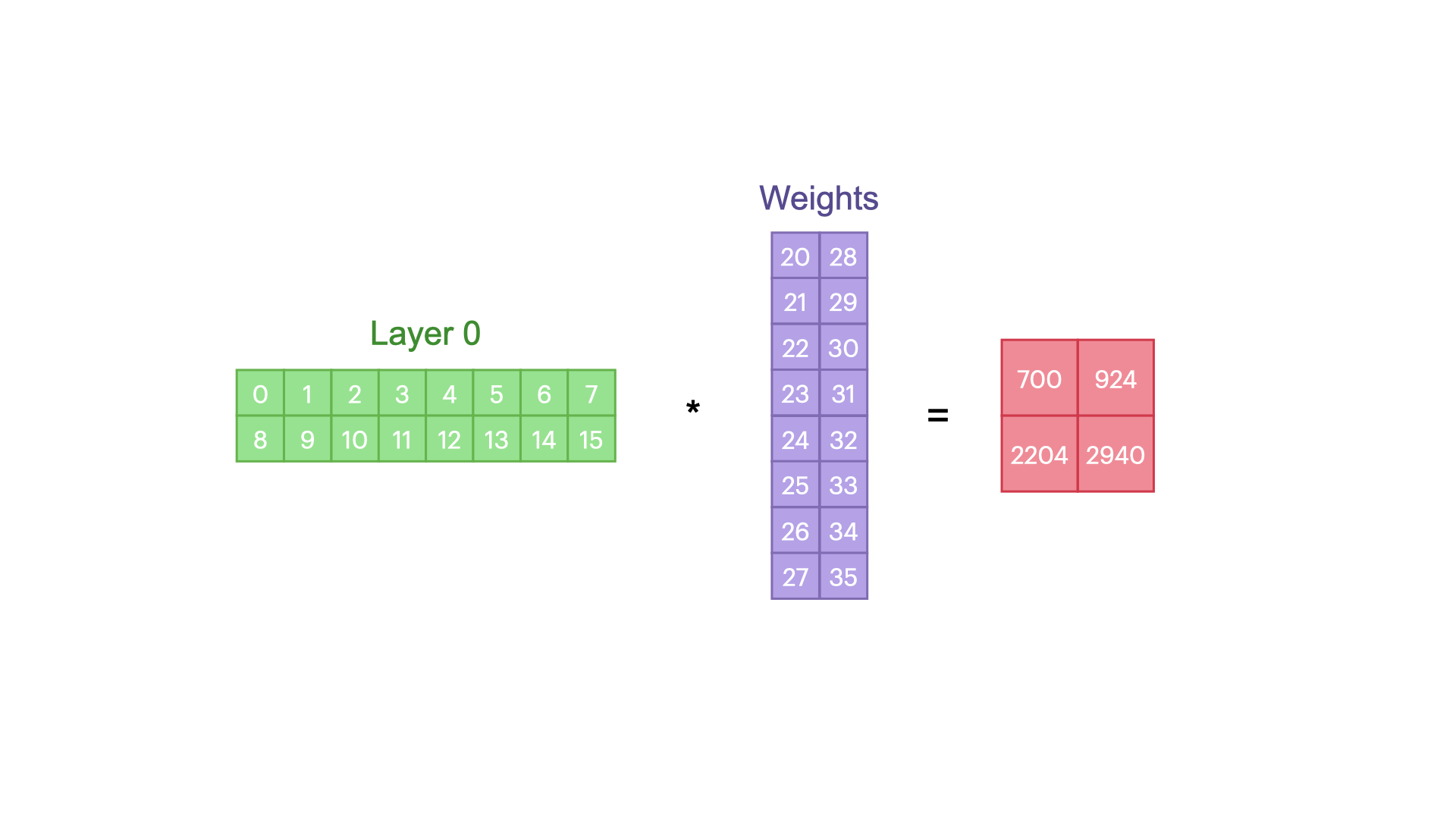
Distributed Data Parallel (DDP)
DDP
is a method in parallel computing used to train deep learning models
across multiple GPUs or nodes efficiently.
DDP
DDP
DDP
DDP
DDP
DDP
DDP
DDP
If you’re scaling DDP to use multiple nodes, the underlying principle
remains the same as single-node multi-GPU training.
DDP
DDP recap
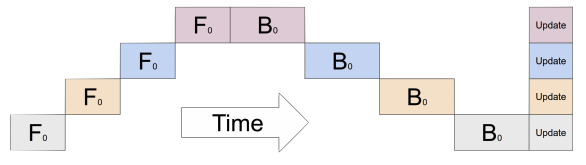
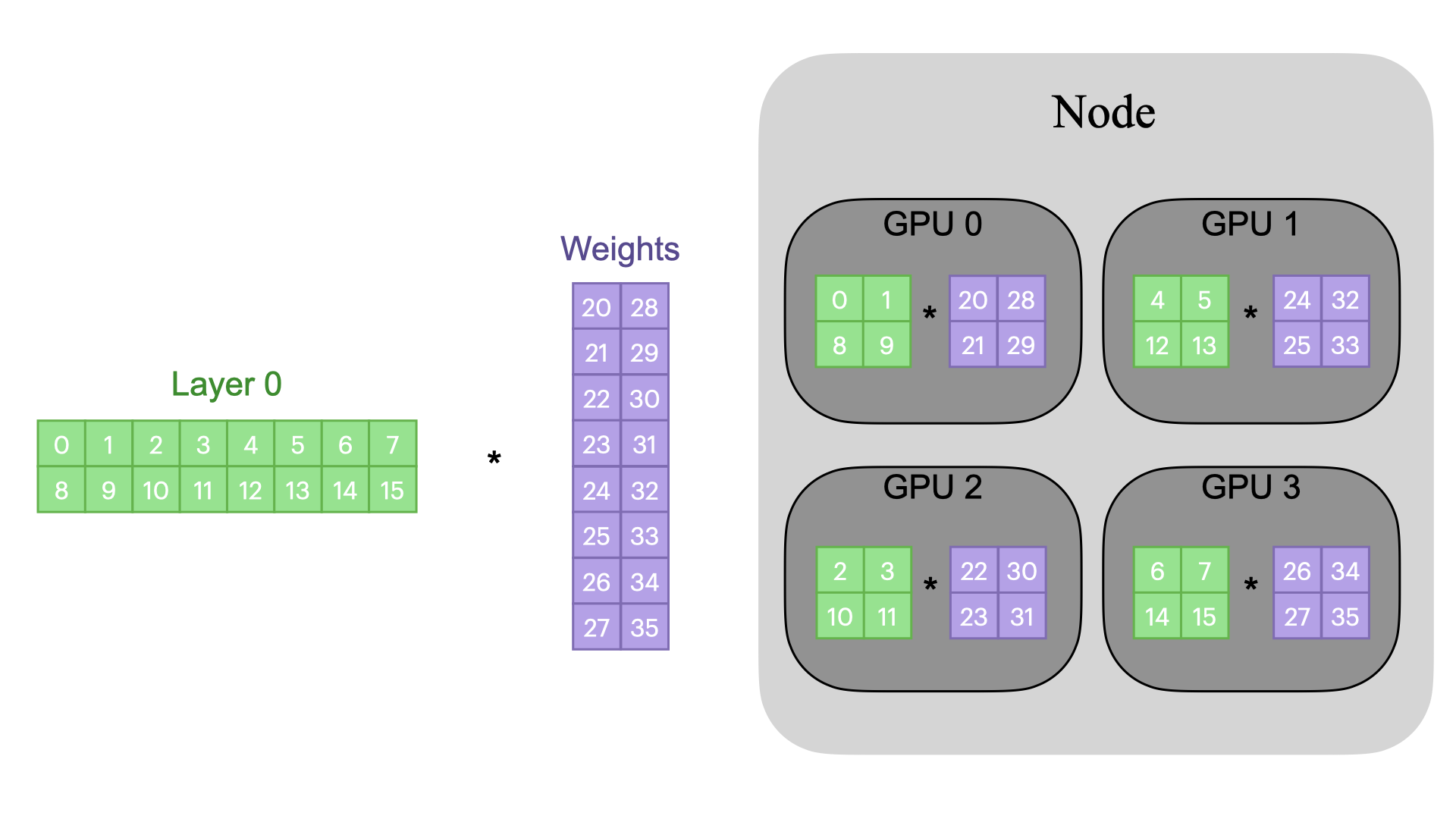
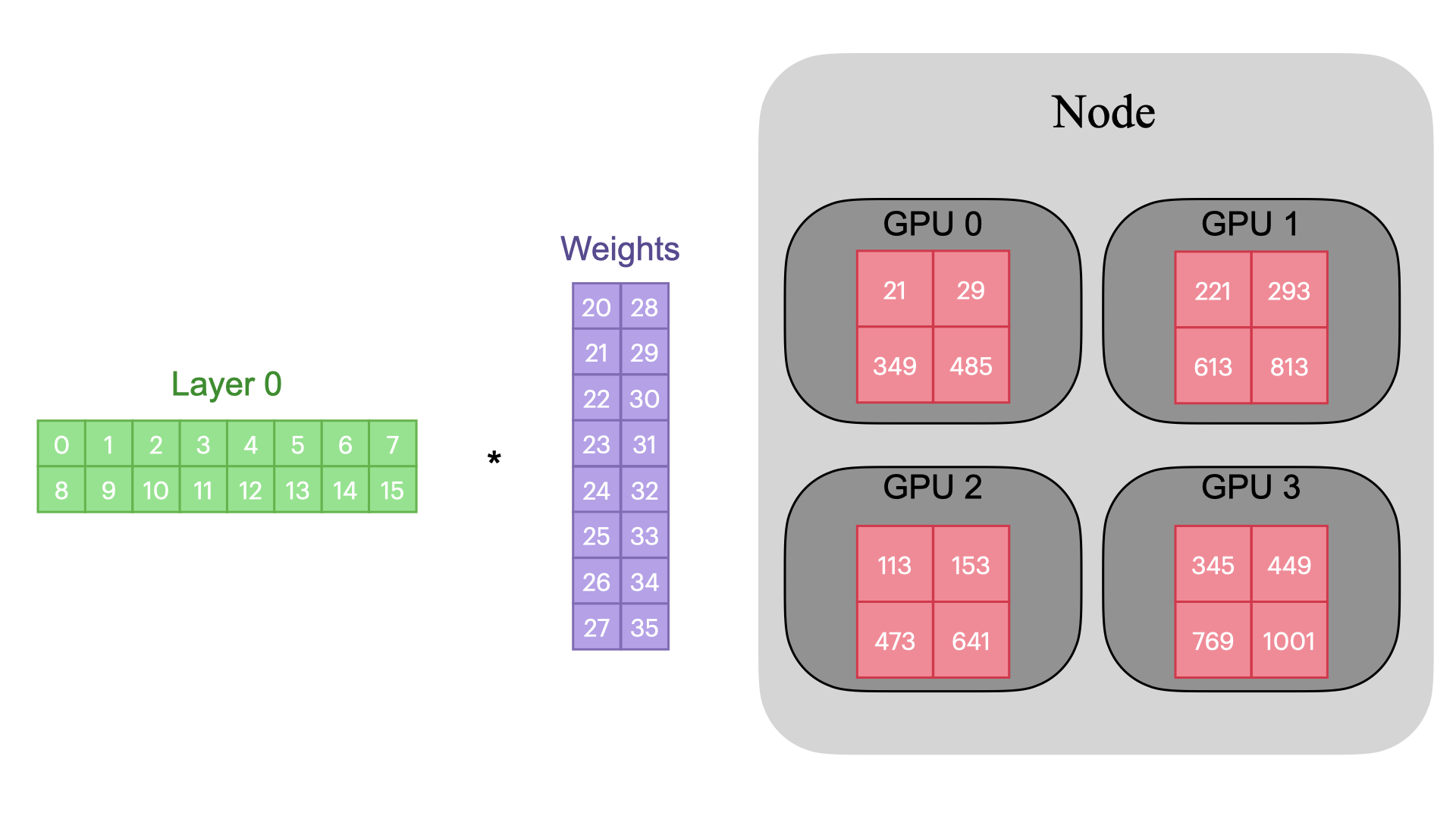
Each GPU on each node gets its own process.
Each GPU has a copy of the model.
Each GPU has visibility into a subset of the
overall dataset and will only see that subset.
Each process performs a full forward and backward
pass in parallel and calculates its gradients.
The gradients are synchronized and averaged across
all processes.
Each process updates its optimizer.
Let’s start coding!
Whenever you see TODOs💻📝,
follow the instructions to either copy-paste the code at the specified
line numbers or type it yourself.
Depending on how you copy and paste, the line
numbers may vary, but always refer to the TODO numbers in the code and
slides.
Setup communication
We need to setup a communication among the
GPUs.
For that we would need the file
distributed_utils.py.
TODOs💻📝:
Import
distributed_utils file at line 13:
# This file contains utility_functions for distributed training.from distributed_utils import*
and add at line 77 a call to
the method setup() defined in
distributed_utils.py:
# Initialize a communication group and return the right identifiers.local_rank, rank, device = setup()
Setup communication
What is in the setup() method ?
def setup():# Initializes a communication group using 'nccl' as the backend for GPU communication. torch.distributed.init_process_group(backend='nccl')# Get the identifier of each process within a node local_rank =int(os.getenv('LOCAL_RANK'))# Get the global identifier of each process within the distributed system rank =int(os.environ['RANK'])# Creates a torch.device object that represents the GPU to be used by this process. device = torch.device('cuda', local_rank)# Sets the default CUDA device for the current process, # ensuring all subsequent CUDA operations are performed on the specified GPU device. torch.cuda.set_device(device)# Different random seed for each process. torch.random.manual_seed(1000+ torch.distributed.get_rank())return local_rank, rank, device
Model
TODO 4💻📝:
At line 83, wrap the model in a
DistributedDataParallel (DDP) module to parallelize the
training across multiple GPUs.
# Wrap the model in DistributedDataParallel module model = torch.nn.parallel.DistributedDataParallel( model, device_ids=[local_rank],)
DistributedSampler
TODO 5💻📝:
At line 94, instantiate a
DistributedSampler object for each set to ensure that
each process gets a different subset of the data.
# DistributedSampler object for each set to ensure that each process gets a different subset of the data.train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True, seed=args.seed)val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset)test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
DataLoader
TODO 6💻📝:
At line 103, REMOVEshuffle=True in the DataLoader of
train_loader and REPLACE it by
sampler=train_sampler
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, # pass the sampler argument to the DataLoader num_workers=int(os.getenv('SLURM_CPUS_PER_TASK')), pin_memory=True)
DataLoader
TODO 7💻📝:
At line 108, pass val_sampler
to the sampler argument of the val_dataLoader
val_loader = DataLoader(val_dataset, batch_size=args.batch_size, sampler=val_sampler, # pass the sampler argument to the DataLoader pin_memory=True)
TODO 8💻📝:
At line 112, pass test_sampler
to the sampler argument of the test_dataLoader
test_loader = DataLoader(test_dataset, batch_size=args.test_batch_size, sampler=test_sampler, # pass the sampler argument to the DataLoader pin_memory=True)
Sampler
TODO 9💻📝:
At line 125, set the current
epoch for the dataset sampler to ensure proper data shuffling in each
epoch
# Pass the current epoch to the sampler to ensure proper data shuffling in each epochtrain_sampler.set_epoch(epoch)
All Reduce Operation
TODO 10💻📝:
At lines 49 and 72, Obtain the
global average loss across the GPUs.
# Return the global average loss.torch.distributed.all_reduce(result, torch.distributed.ReduceOp.AVG)
print
TODO 11💻📝:
At lines 133, 144, and 148,
replace all the print methods by
print0 method defined in
distributed_utils.py to allow only rank 0
to print in the output file.
# We use the utility function print0 to print messages only from rank 0.print0(f'[{epoch+1}/{args.epochs}] Train loss: {train_loss:.5f}, validation loss: {val_loss:.5f}')
# We use the utility function print0 to print messages only from rank 0.print0('Finished training after', end_time - start_time, 'seconds.')
# We use the utility function print0 to print messages only from rank 0.print0('Final test loss:', test_loss.item())
print
The definition of the function print0 is in
distributed_utils.py
functools.lru_cache(maxsize=None)def is_root_process():"""Return whether this process is the root process."""return torch.distributed.get_rank() ==0def print0(*args, **kwargs):"""Print something only on the root process."""if is_root_process():print(*args, **kwargs)
Save model
TODO 12💻📝:
At lines 138 and 151, replace
torch.save method with the utility function save0 to allow only the
process with rank 0 to save the model.
# We allow only rank=0 to save the modelsave0(model, 'model-best')
# We allow only rank=0 to save the modelsave0(model, 'model-final')
Save model
The method save0 is defined in
distributed_utils.py
functools.lru_cache(maxsize=None)def is_root_process():"""Return whether this process is the root process."""return torch.distributed.get_rank() ==0def save0(*args, **kwargs):"""Pass the given arguments to `torch.save`, but only on the root process. """# We do *not* want to write to the same location with multiple# processes at the same time.if is_root_process(): torch.save(*args, **kwargs)
We are almost there
That’s it for the train.py
file.
But before launching our job, we need to add some
lines to run_train.sbatch file
Setup communication
In run_train.sbatch file:
TODOs 13💻📝:
At line 3, increase the number of GPUs to 4 if
it is not already done.
#SBATCH --gres=gpu:4
At line 22, pass the correct number of
devices.
exportCUDA_VISIBLE_DEVICES=0,1,2,3
Setup communication
Stay in run_train.sbatch file:
TODO 14💻📝: we need to setup
MASTER_ADDR and MASTER_PORT to allow
communication over the system.
At line 24, add the following:
# Extracts the first hostname from the list of allocated nodes to use as the master address.MASTER_ADDR="$(scontrol show hostnames "$SLURM_JOB_NODELIST"|head-n 1)"# Modifies the master address to allow communication over InfiniBand cells.MASTER_ADDR="${MASTER_ADDR}i"# Get IP for hostname.exportMASTER_ADDR="$(nslookup"$MASTER_ADDR"|grep-oP'(?<=Address: ).*')"exportMASTER_PORT=7010
Setup communication
We are not done yet with
run_train.sbatch file:
TODO 15💻📝:
At line 35, we change the lauching script to use
torchrun_jsc and pass the following argument:
# Launch a distributed training job across multiple nodes and GPUssrun--cpu_bind=none bash -c"torchrun_jsc \ --nnodes=$SLURM_NNODES\ --rdzv_backend c10d \ --nproc_per_node=gpu \ --rdzv_id $RANDOM\ --rdzv_endpoint=$MASTER_ADDR:$MASTER_PORT\ --rdzv_conf=is_host=\$(if ((SLURM_NODEID)); then echo 0; else echo 1; fi) \ train.py "
Setup communication
The arguments that we pass are:
nnodes=$SLURM_NNODES:
the number of nodes
rdzv_backend c10d:
the c10d method for coordinating the setup of communication among
distributed processes.
nproc_per_node=gpu
the number of GPUs
rdzv_id $RANDOM a
random id which that acts as a central point for initializing and
coordinating the communication among different nodes participating in
the distributed training.
rdzv_endpoint=$MASTER_ADDR:$MASTER_PORT
the IP that we setup in the previous slide to ensure all nodes know
where to connect to start the training session.
rdzv_conf=is_host=\$(if ((SLURM_NODEID)); then echo 0; else echo 1; fi)
The rendezvous host which is responsible for coordinating the initial
setup of communication among the nodes.
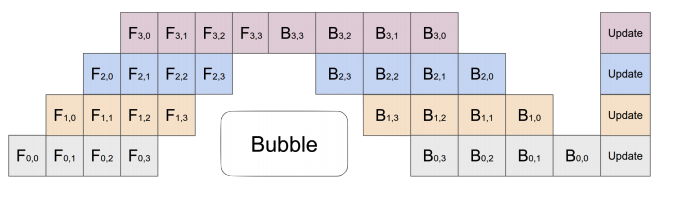
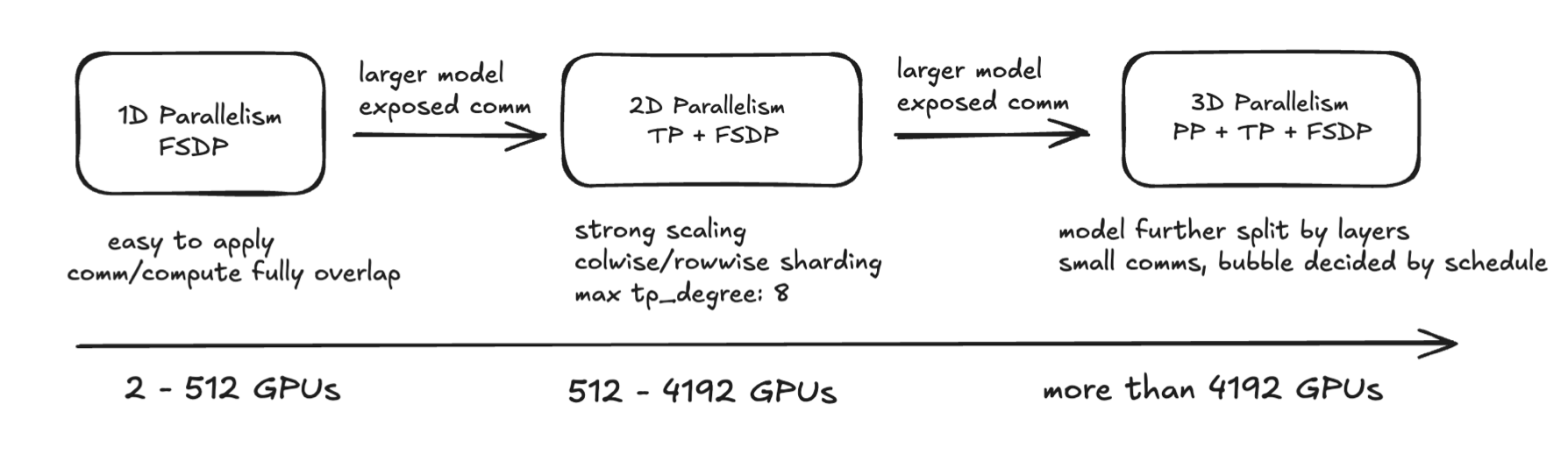
3D Parallelism combines Tensor Parallelism (TP),
Pipeline Parallelism (PP), and Data Parallelism (DP) to efficiently
train large models by distributing computation, memory, and data across
multiple GPUs.
It enables scaling to very large models by
addressing compute, memory, and communication bottlenecks in a balanced
way.
Day 2 RECAP
You know where to store your code and your data.
🗂️
How to create HDF5 and PyArrow files. 📄
You know what distributed training is. 🧑💻
You can submit training jobs on a single GPU,
multiple GPUs, or across multiple nodes. 🎮💻
You are familiar with DDP and aware of other
distributed training techniques like FSDP, TP, PP, and 3D parallelism.
⚙️💡
You know how to monitor your training using llview.
📊👀