Bringing Deep Learning Workloads to JSC supercomputers
Data loading
June 25, 2024

Jülich Supercomputers
- Our I/O server is almost a supercomputer by itself
![JSC Supercomputer Stragegy]()
Data loading

The ImageNet dataset
Large Scale Visual Recognition Challenge (ILSVRC)
- An image dataset organized according to the WordNet hierarchy.
- Extensively used in algorithms for object detection and image classification at large scale.
- It has 1000 classes, that comprises 1.2 million images for training, and 50,000 images for the validation set.

Inodes
- Inodes (Index Nodes) are data structures that store metadata about files and directories.
- Unique identification of files and directories within the file system.
- Efficient management and retrieval of file metadata.
- Essential for file operations like opening, reading, and writing.
- Limitations:
- Fixed Number: Limited number of inodes; no new files if exhausted, even with free disk space.
- Space Consumption: Inodes consume
disk space, balancing is needed for efficiency.
![]()

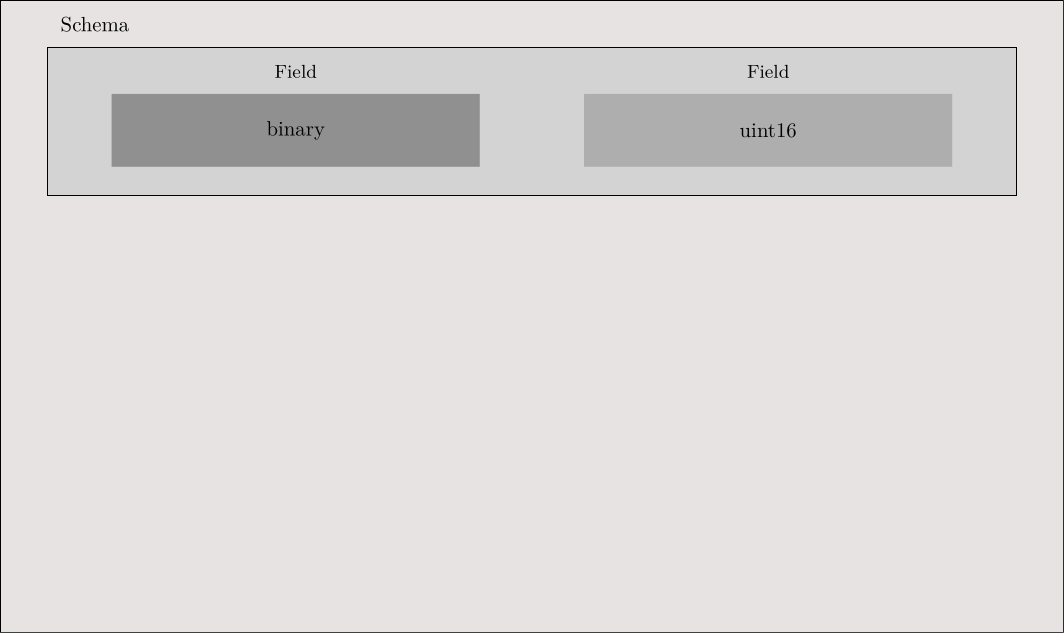
Pyarrow File Creation

binary_t = pa.binary()
uint16_t = pa.uint16()Pyarrow File Creation

binary_t = pa.binary()
uint16_t = pa.uint16()
schema = pa.schema([
pa.field('image_data', binary_t),
pa.field('label', uint16_t),
])Pyarrow File Creation
with pa.OSFile(
os.path.join(args.target_folder, f'ImageNet-{split}.arrow'),
'wb',
) as f:
with pa.ipc.new_file(f, schema) as writer:Pyarrow File Creation
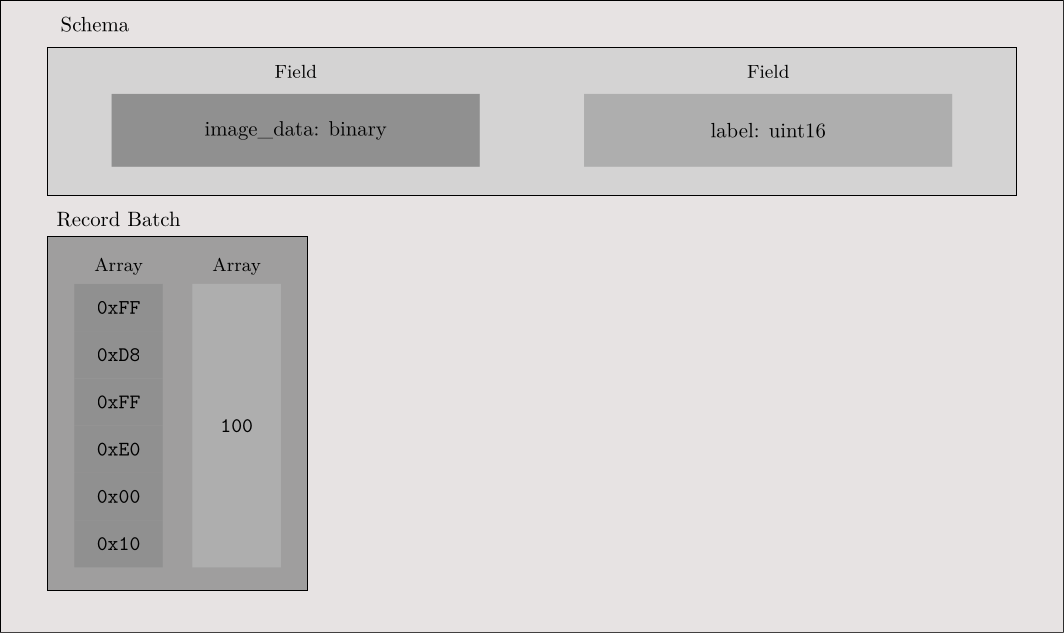
with open(sample, 'rb') as f:
img_string = f.read()
image_data = pa.array([img_string], type=binary_t)
label = pa.array([label], type=uint16_t)
batch = pa.record_batch([image_data, label], schema=schema)
writer.write(batch)Pyarrow File Creation
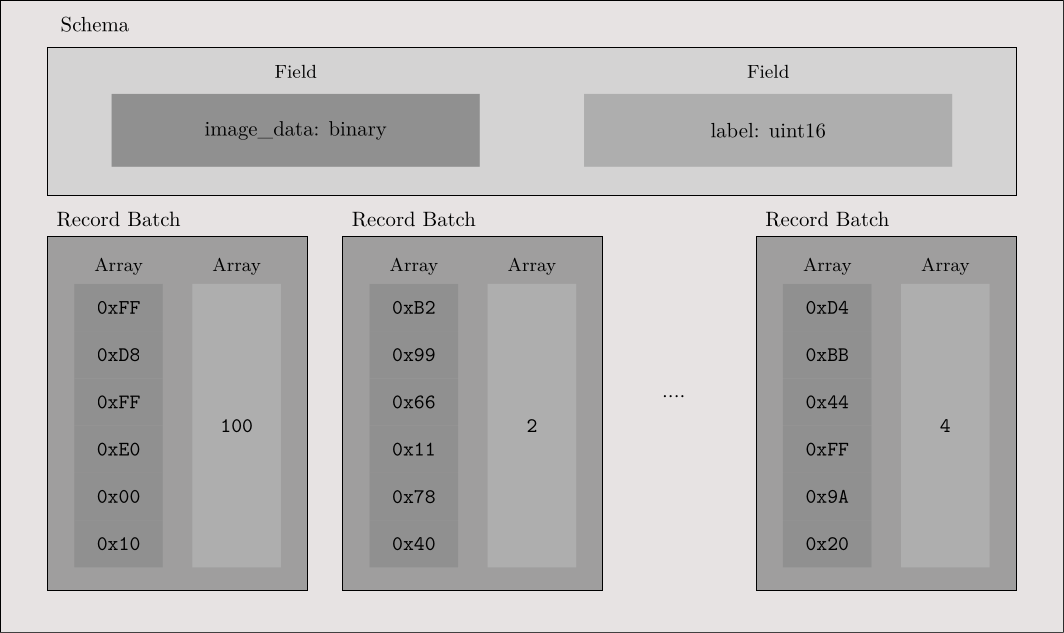
with open(sample, 'rb') as f:
img_string = f.read()
image_data = pa.array([img_string], type=binary_t)
label = pa.array([label], type=uint16_t)
batch = pa.record_batch([image_data, label], schema=schema)
writer.write(batch)Access Arrow File
def __getitem__(self, idx):
if self.arrowfile is None:
self.arrowfile = pa.OSFile(self.data_root, 'rb')
self.reader = pa.ipc.open_file(self.arrowfile)
row = self.reader.get_batch(idx)
img_string = row['image_data'][0].as_py()
target = row['label'][0].as_py()
with io.BytesIO(img_string) as byte_stream:
with Image.open(byte_stream) as img:
img = img.convert("RGB")
if self.transform:
img = self.transform(img)
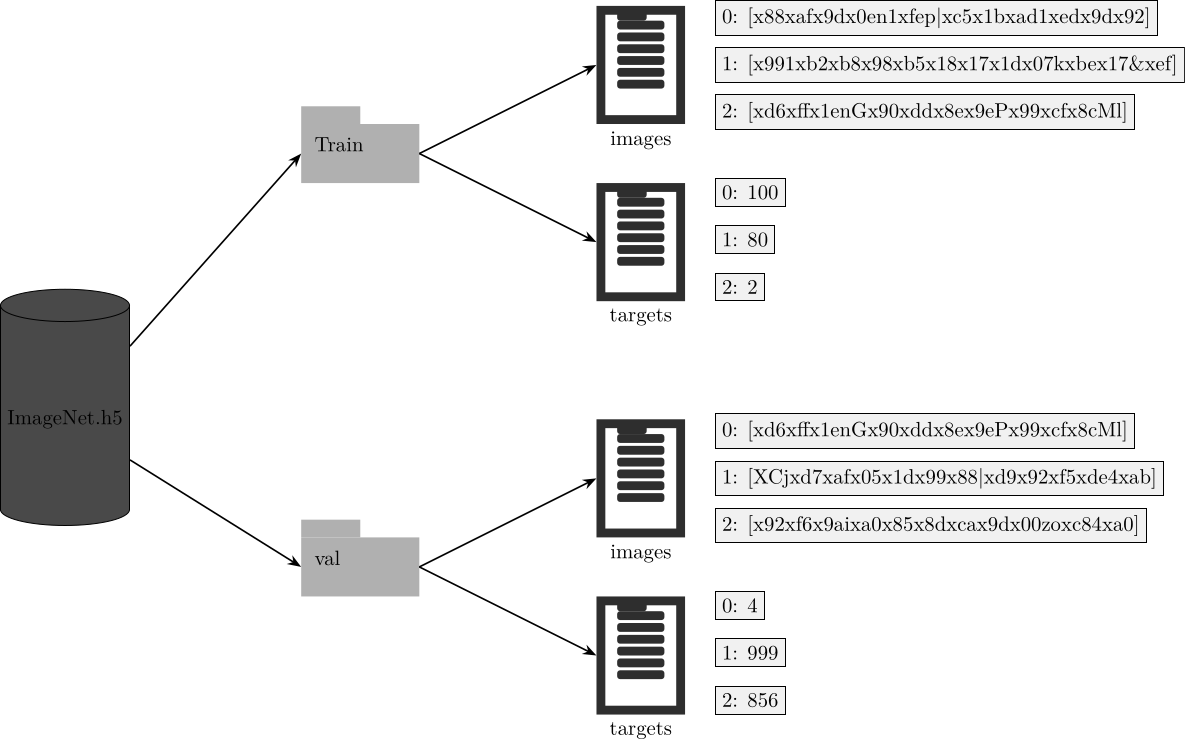
return img, targetHDF5

with h5py.File(os.path.join(args.target_folder, 'ImageNet.h5'), "w") as f:HDF5
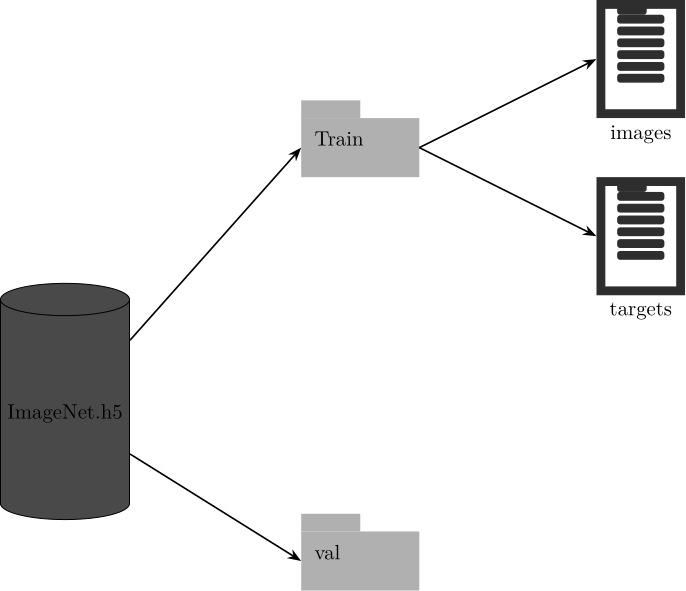
group = g.create_group(split)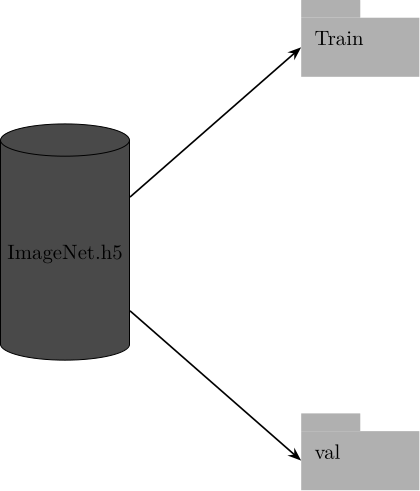
HDF5
dt_sample = h5py.vlen_dtype(np.dtype(np.uint8))
dt_target = np.dtype('int16')
dset = group.create_dataset(
'images',
(len(samples),),
dtype=dt_sample,
)
dtargets = group.create_dataset(
'targets',
(len(samples),),
dtype=dt_target,
)
HDF5
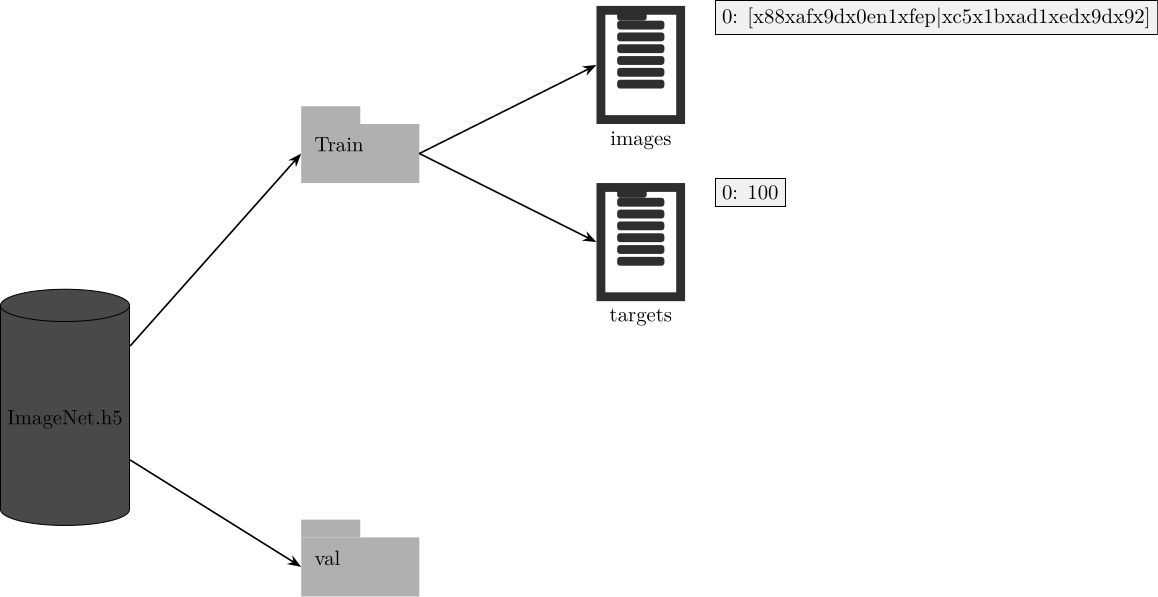
for idx, (sample, target) in tqdm(enumerate(zip(samples, targets))):
with open(sample, 'rb') as f:
img_string = f.read()
dset[idx] = np.array(list(img_string), dtype=np.uint8)
dtargets[idx] = targetHDF5
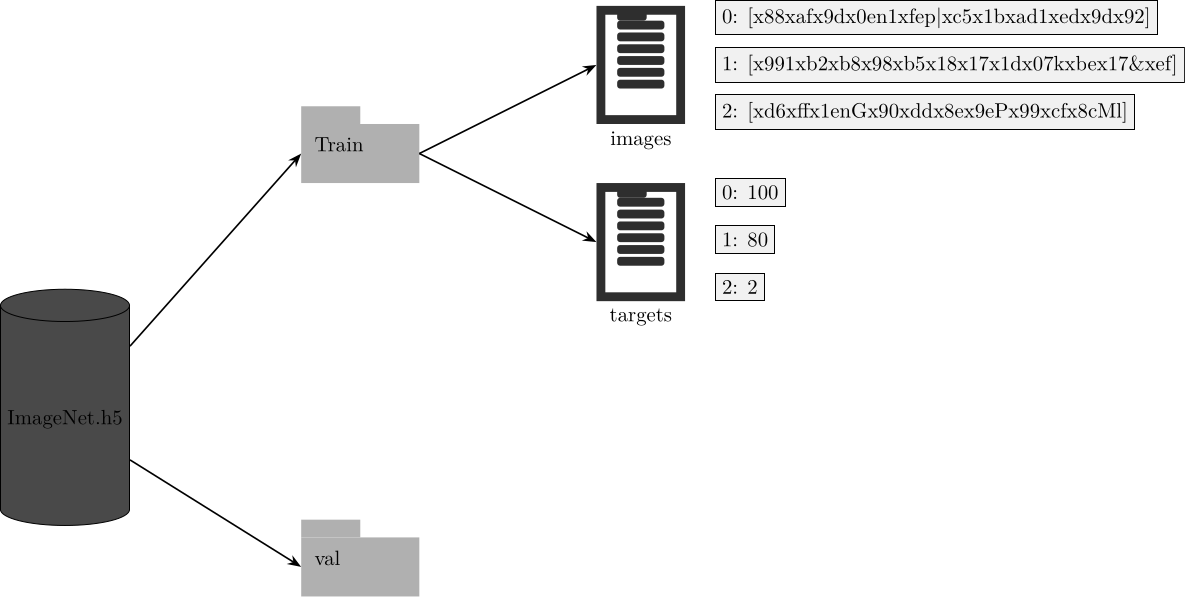
for idx, (sample, target) in tqdm(enumerate(zip(samples, targets))):
with open(sample, 'rb') as f:
img_string = f.read()
dset[idx] = np.array(list(img_string), dtype=np.uint8)
dtargets[idx] = targetHDF5