Bringing Deep Learning Workloads to JSC supercomputers
Speedup Data loading
Alexandre Strube // Sabrina Benassou
March 13, 2024
Schedule for day 2
| Time | Title |
|---|---|
| 10:00 - 10:15 | Welcome, questions |
| 10:15 - 11:30 | Speedup data loading |
| 11:30 - 12:00 | Coffee Break (flexible) |
| 12:30 - 14:00 | Parallelize Training |
Let’s talk about DATA
- Some general considerations one should have in mind

I/O is separate and shared
All compute nodes of all supercomputers see the same files
- Performance tradeoff between shared acessibility and speed
- It’s simple to load data fast to 1 or 2 gpus. But to 100? 1000? 10000?
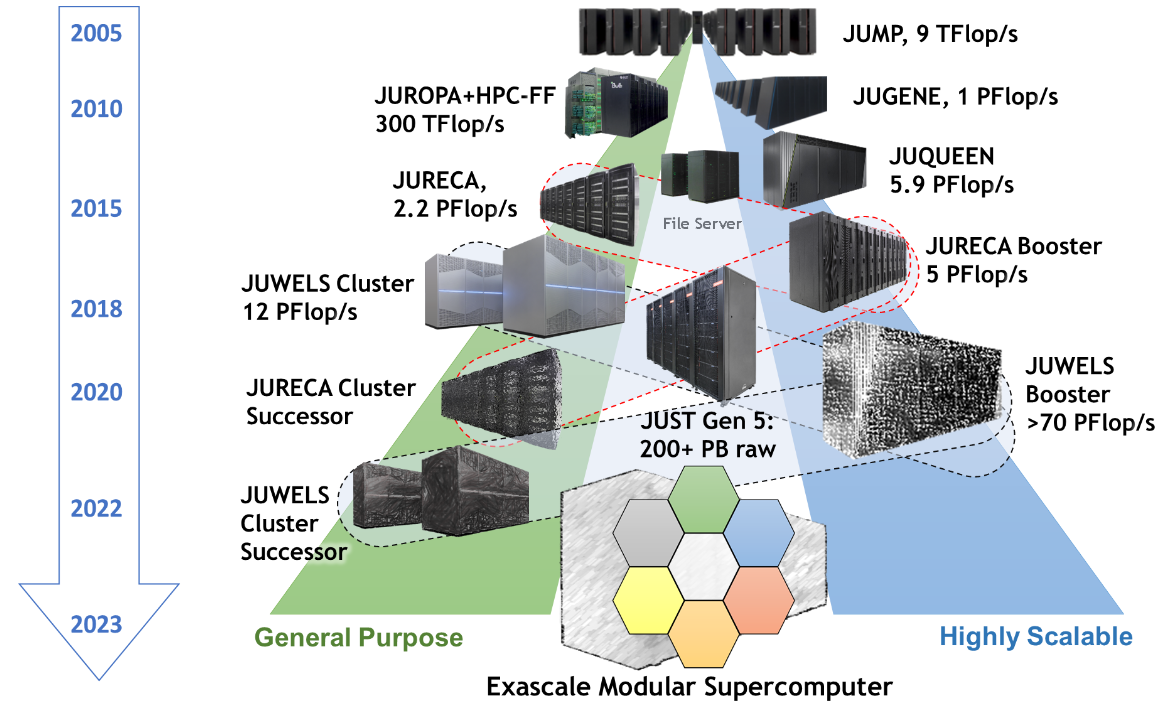
Jülich Supercomputers
- Our I/O server is almost a supercomputer by itself
![JSC Supercomputer Stragegy]()
JSC Supercomputer Stragegy
Where do I keep my files?
$PROJECT_projectnamefor code- Most of your work should stay here
$DATA_projectnamefor big data(*)- Permanent location for big datasets
$SCRATCH_projectnamefor temporary files (fast, but not permanent)- Files are deleted after 90 days untouched
Data services
- JSC provides different data services
- Data projects give massive amounts of storage
- We use it for ML datasets. Join the project at Judoor
- After being approved, connect to the supercomputer and try it:
Data Staging
- LARGEDATA
filesystem is not accessible by compute nodes
- Copy files to an accessible filesystem BEFORE working
- Imagenet-21K copy alone takes 21+ minutes to
$SCRATCH
- We already copied it to $SCRATCH for you
Data loading

Strategies
- We have CPUs and lots of memory - let’s use them
- multitask training and data loading for the next batch
/dev/shmis a filesystem on ram - ultra fast ⚡️
- Use big files made for parallel computing
- HDF5, Zarr, mmap() in a parallel fs, LMDB
- Use specialized data loading libraries
- FFCV, DALI, Apache Arrow
- Compression sush as squashfs
- data transfer can be slower than decompression (must be checked case by case)
- Beneficial in cases where numerous small files are at hand.
Libraries
- Apache Arrow https://arrow.apache.org/
- FFCV https://github.com/libffcv/ffcv and FFCV for PyTorch-Lightning
- Nvidia’s DALI https://developer.nvidia.com/dali
We need to download some code
The ImageNet dataset
Large Scale Visual Recognition Challenge (ILSVRC)
- An image dataset organized according to the WordNet hierarchy.
- Extensively used in algorithms for object detection and image classification at large scale.
- It has 1000 classes, that comprises 1.2 million images for training, and 50,000 images for the validation set.

The ImageNet dataset
imagenet_class_index.json
ILSVRC2012_val_labels.json
ILSVRC
|-- Data/
`-- CLS-LOC
|-- imagenet_labels.pkl
|-- imagenet_val.pkl
|-- test
|-- train
| |-- n01440764
| | |-- n01440764_10026.JPEG
| | |-- n01440764_10027.JPEG
| | |-- n01440764_10029.JPEG
| |-- n01695060
| | |-- n01695060_10009.JPEG
| | |-- n01695060_10022.JPEG
| | |-- n01695060_10028.JPEG
| | |-- ...
| |...
|-- val
|-- ILSVRC2012_val_00000001.JPEG
|-- ILSVRC2012_val_00016668.JPEG
|-- ILSVRC2012_val_00033335.JPEG
|-- ...Access File System
class ImageNet(Dataset):
def __init__(self, root, split, transform=None):
self.samples = []
self.targets = []
self.transform = transform
self.syn_to_class = {}
with open(os.path.join(root, "imagenet_class_index.json"), "rb") as f:
json_file = json.load(f)
for class_id, v in json_file.items():
self.syn_to_class[v[0]] = int(class_id)
with open(os.path.join(root, "ILSVRC2012_val_labels.json"), "rb") as f:
self.val_to_syn = json.load(f)
samples_dir = os.path.join(root, "ILSVRC/Data/CLS-LOC", split)
for entry in os.listdir(samples_dir):
if split == "train":
syn_id = entry
target = self.syn_to_class[syn_id]
syn_folder = os.path.join(samples_dir, syn_id)
for sample in os.listdir(syn_folder):
sample_path = os.path.join(syn_folder, sample)
self.samples.append(sample_path)
self.targets.append(target)
elif split == "val":
syn_id = self.val_to_syn[entry]
target = self.syn_to_class[syn_id]
sample_path = os.path.join(samples_dir, entry)
self.samples.append(sample_path)
self.targets.append(target) Access File System
Pyarrow
def save_arrow(args, splits, train_samples, train_targets, val_samples, val_targets):
binary_t = pa.binary()
uint16_t = pa.uint16()
schema = pa.schema([
pa.field('image_data', binary_t),
pa.field('label', uint16_t),
])
for split in splits:
if split == "train":
samples = train_samples
targets = train_targets
else:
samples = val_samples
targets = val_targets
with pa.OSFile(
os.path.join(args.target_folder, f'ImageNet-{split}.arrow'),
'wb',
) as f:
with pa.ipc.new_file(f, schema) as writer:
for (sample, label) in zip(samples, targets):
with open(sample, 'rb') as f:
img_string = f.read()
image_data = pa.array([img_string], type=binary_t)
label = pa.array([label], type=uint16_t)
batch = pa.record_batch([image_data, label], schema=schema)
writer.write(batch)Access Arrow File
class ImageNetArrow(Dataset):
def __init__(self, data_root, transform):
self.data_root = data_root
self.transform = transform
self.arrowfile = None
self.reader = None
with pa.OSFile(self.data_root, 'rb') as f:
with pa.ipc.open_file(f) as reader:
self._len = reader.num_record_batches
def __len__(self):
return self._len
def __getitem__(self, idx):
if self.arrowfile is None:
self.arrowfile = pa.OSFile(self.data_root, 'rb')
self.reader = pa.ipc.open_file(self.arrowfile)
row = self.reader.get_batch(idx)
img_string = row['image_data'][0].as_py()
target = row['label'][0].as_py()
with io.BytesIO(img_string) as byte_stream:
with Image.open(byte_stream) as img:
img = img.convert("RGB")
if self.transform:
img = self.transform(img)
return img, targetHDF5
def save_h5(splits, train_samples, train_targets, val_samples, val_targets):
with h5py.File(os.path.join(args.target_folder, 'ImageNet.h5'), "w") as f:
for split in splits:
if split == "train":
samples = train_samples
targets = train_targets
else:
samples = val_samples
targets = val_targets
group = f.create_group(split)
dt_sample = h5py.vlen_dtype(np.dtype(np.uint8))
dt_target = np.dtype('int16')
dset = group.create_dataset(
'images',
(len(samples),),
dtype=dt_sample,
)
dtargets = group.create_dataset(
'targets',
(len(samples),),
dtype=dt_target,
)
for idx, (sample, target) in tqdm(enumerate(zip(samples, targets))):
with open(sample, 'rb') as f:
img_string = f.read()
dset[idx] = np.array(list(img_string), dtype=np.uint8)
dtargets[idx] = target
Access h5 File
class ImageNetH5(Dataset):
def __init__(self, train_data_path, split, transform=None):
self.train_data_path = train_data_path
self.split = split
self.h5file = None
self.imgs = None
self.targets = None
with h5py.File(train_data_path, 'r') as h5file:
self._len = len(h5file[split]["images"])
self.transform = transform
def __len__(self) -> int:
return self._len
def __getitem__(self, idx):
if self.h5file is None:
self.h5file = h5py.File(self.train_data_path, 'r')[self.split]
self.imgs = self.h5file["images"]
self.targets = self.h5file["targets"]
img_string = self.imgs[idx]
target = self.targets[idx]
with io.BytesIO(img_string) as byte_stream:
with Image.open(byte_stream) as img:
img = img.convert("RGB")
if self.transform:
img = self.transform(img)
return img, targetResults and Conclusion
File system access: 00:04:27
H5 file access: 00:03:31
Arrow file access: 00:03:16
While reading the data from the H5 file or the arrow file is a bit faster than reading the data from the file system, it is still useful in cases where you have a lot of small files and not enough inodes.
DEMO
Exercise
- Could you create an arrow file for the flickr
dataset stored in
/p/scratch/training2402/data/Flickr30K/and read it using a dataloader ?