Speedup Data loading
Speedup Data loading
Alexandre Strube // Sabrina Benassou
October 17, 2023
Let’s talk about DATA
- Some general considerations one should have in mind

I/O is separate and shared
All compute nodes of all supercomputers see the same files
- Performance tradeoff between shared acessibility and speed
- It’s simple to load data fast to 1 or 2 gpus. But to 100? 1000? 10000?
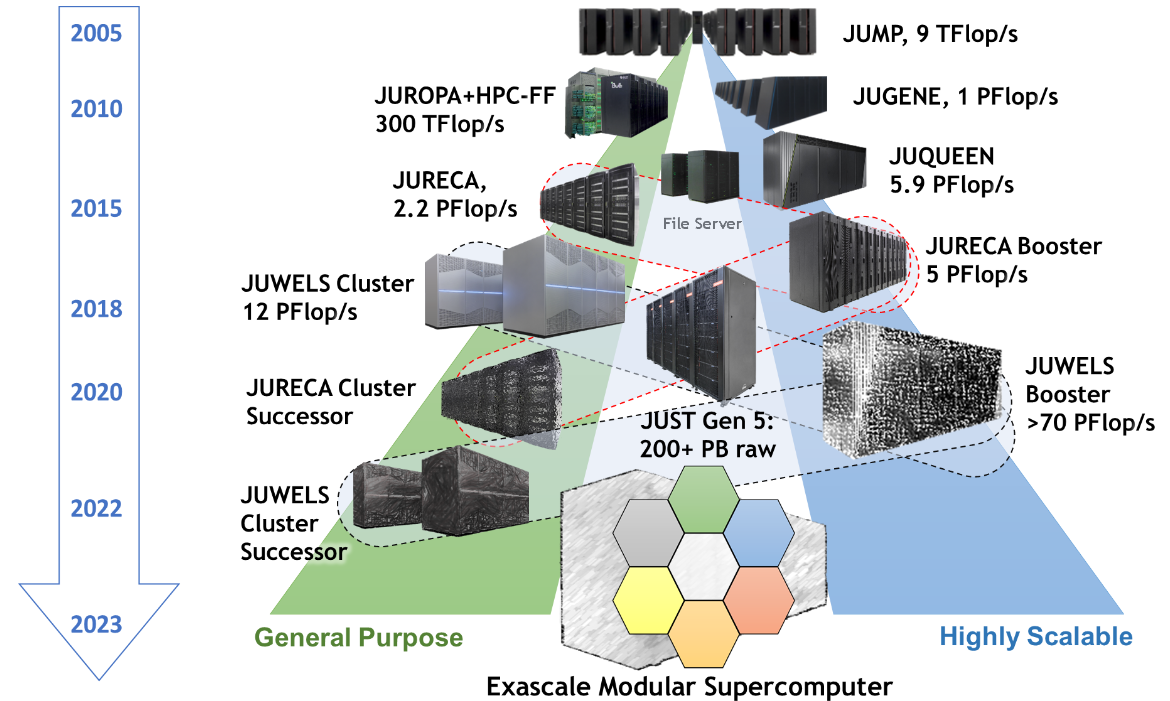
Jülich Supercomputers
- Our I/O server is almost a supercomputer by itself
![JSC Supercomputer Stragegy]()
JSC Supercomputer Stragegy
Where do I keep my files?
$PROJECT_projectnamefor code- Most of your work should stay here
$DATA_projectnamefor big data(*)- Permanent location for big datasets
$SCRATCH_projectnamefor temporary files (fast, but not permanent)- Files are deleted after 90 days untouched
Data services
- JSC provides different data services
- Data projects give massive amounts of storage
- We use it for ML datasets. Join the project at Judoor
- After being approved, connect to the supercomputer and try it:
Data Staging
- LARGEDATA
filesystem is not accessible by compute nodes
- Copy files to an accessible filesystem BEFORE working
- Imagenet-21K copy alone takes 21+ minutes to
$SCRATCH
- We already copied it to $SCRATCH for you
Data loading

Strategies
- We have CPUs and lots of memory - let’s use them
- multitask training and data loading for the next batch
/dev/shmis a filesystem on ram - ultra fast ⚡️
- Use big files made for parallel computing
- HDF5, Zarr, mmap() in a parallel fs, LMDB
- Use specialized data loading libraries
- FFCV, DALI, Apache Arrow
- Compression sush as squashfs
- data transfer can be slower than decompression (must be checked case by case)
- Beneficial in cases where numerous small files are at hand.
Libraries
- Apache Arrow https://arrow.apache.org/
- FFCV https://github.com/libffcv/ffcv and FFCV for PyTorch-Lightning
- Nvidia’s DALI https://developer.nvidia.com/dali